LR 파싱
기계어나 어셈블리어가 아닌, 인간이 이해하기 쉬운 언어(이른바 고급 프로그래밍 언어)에 대한 열망은 컴파일러compiler라는 도구의 개발로 이어졌다.
컴파일러가 하는 일이, 고급 언어로 작성된 프로그램 소스 코드를 기계어로 변환해주는 것이라고 이해되고 있지만 원래 처음 의도는 그 단어compile가 의미하는 것처럼 코드를 차곡차곡 모으는 것이었다.7 왜냐하면 처음에는 소스 코드가 단순히 서브루틴 이름들의 나열이었기 때문이었다. 그래서 그 이름에 해당하는 서브루틴 기계어 코드들을 순서대로 배열하는 것이 컴파일러의 역할이었다.
하지만 포트란과 알골이 등장하면서 컴파일러는 진화해야 했다. 고급 언어로 작성된 소스 코드는 기계어로 일대일 변환이 가능하지 않았다. 기술된 코드의 의미를 이해해서 적합한 기계어들로 바꿔주어야 했다. 이를 위해서 컴파일러는 몇 개의 단계를 거치도록 구성되었다.
첫 단계는 어휘분석Lexical analysis이라고 부른다. 컴파일러 입장에서 소스 코드는 그저 문자들이 길게 나열된 것에 불과하다. 이 문자들을 한 글자씩 읽어가면서 의미 있는 단위로 분절한다. 예를 들어 문자열, 기호 등이 구별되어 관리된다. 이렇게 구별된 각각을 토큰token이라고 부른다. 아래의 예는 어휘분석을 통해 확인된 토큰들을 보여주고 있다.
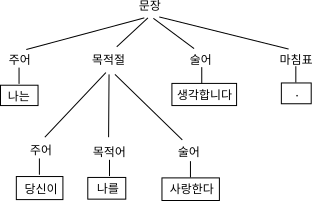
나는 당신을 사랑합니다. => 나는, 당신을, 사랑합니다, .
if (i > 0) then i = i - 1; => if, (, i, >, 0, ), then, i, =, i, -, 1, ;이제 소스 코드는 문자들의 나열이 아니라 토큰들의 나열로 바뀌어 있다. 컴파일러는 토큰들의 나열에서 이 프로그래밍 언어의 문법 규칙에 맞는 구조를 찾아낸다. 이를 구문분석Syntax analysis 또는 파싱Parsing이라고 부른다. 이 과정에서 문법에 맞지 않게 작성된 코드를 검출할 수 있다.
파싱이란 결국 프로그램 소스 코드에 적혀 있는 문자들의 나열 속에서 문법 규칙에 들어 맞는 구조를 찾아내는 일이다. 한국어를 예로 들어 보겠다. 한국어에서 문장을 구성하는 문법은 다음과 같다.(물론 훨씬 많은 문법 규칙이 있겠으나 여기서는 편의상 두 개만 들어 보겠다.)
(1) 문장 -> 주어 + 술어 + 마침표
(2) 문장 -> 주어 + 목적어 + 술어 + 마침표이제 ‘나는 당신을 사랑합니다.‘라는 문장이 주어지면 파서(파싱 작업을 하는 프로그램)가 해야 할 일은, 이 문장을 만족시키는 문법 규칙을 찾아내는 것이다. (1)번 규칙은 맞아떨어지지 않지만 (2)번 규칙은 맞아떨어진다. 따라서 이 문장은 문법을 만족한다.
‘나는 사랑합니다. 당신을.‘이라는 문장이 주어지면 어떻게 될까? 파서는 이것을 두 개의 문장으로 이해한다. 왜냐하면 마침표가 두 개 있기 때문이다. 첫 번째 문장은 (1)번 규칙에 부합하지만 두 번째 문장으로 인식한 ‘당신을.‘은 (1)번과 (2)번에 모두 해당되지 않는다. 따라서 이 문장들은 문법을 만족시키지 못한다.
파서는, 주어진 문장이 문법에 부합하는지를 검사만 하는 것이 아니라, 문법에 맞게 문장을 재구성한다. 그 결과물을 파싱 트리Parsing tree라고 부르는데 이 구조가 만들어지면 기계어로 변환이 가능해진다. 아래의 예는 파싱 트리의 예를 보여준다.
커누스는 1965년에 <컴퓨터 프로그래밍의 아름다운 세계>의 파싱 부분을 작성하는 과정에서 새로운 아이디어를 생각해냈다. 당시에는 상향식Bottom-up 파싱 기법이 활발하게 연구되고 있었지만 일반 프로그래밍 언어에 사용할 수 있을 정도로 정교하지는 못했다. 그는 보편적으로 적용이 가능한 상향식 파싱 기법을 제안했는데 그것을 LR 파싱이라고 이름 붙였다. 그리고 LR 파싱이 가능하기 위해 어떤 조건이 필요한지를 밝혀냈고, 어떤 언어가 LR 파싱이 가능하다면 이 언어를 처리할 수 있는 DPDA(Deterministic Push-Down Automata)가 존재함을 증명했다.8
LR 파싱에서 LR은 Left-to-right, Rightmost derivation in reverse의 약자이다. 이것을 풀어서 해석하자면 ‘왼쪽에서 오른쪽으로 진행하는데 거꾸로 따지면 오른쪽 끝에서부터 변환’하는 방식이라는 의미가 된다. LR 파싱에 대비되는 것으로 LL 파싱이 있다. 여기서 LL은 Left-to-right, Leftmost derivation의 약자로, ‘왼쪽에서 오른쪽으로 진행하는데 왼쪽 끝에서부터 변환’하는 방식이라는 의미이다. 예를 들어 비교해보겠다. 아래와 같은 문법을 가진 언어가 있다고 가정해보자. 여기서 소문자는 종단terminal 값을 의미하며 대문자는 중간intermediate 값을 의미한다. 그리고 S는 문장 전체를 의미하고  은 아무것도 없음empty을 의미한다.8
은 아무것도 없음empty을 의미한다.8
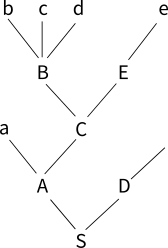
(1) S -> AD
(2) A -> aC
(3) B -> bcd
(4) C -> BE
(5) D ->
(6) E -> e자. 이제 abcde라는 문장이 입력되었다고 해보자. 이 문장은 과연 위의 문법을 만족할까? 다시 말하자면 S에서 시작해서 위의 문법 규칙들을 적용하면 abcde라는 문장을 만들어낼 수 있을까?
a, b, c, d, e는 파서로 입력되는 토큰이라고 생각하면 된다. LR 파싱은 문장을 왼쪽에서부터 오른쪽으로 훑어나가면서 작업을 한다. a로 시작되는 문법 규칙은 (2)가 있다. 하지만 다음 토큰인 b를 보면 (3)번 문법규칙이 해당된다. (2)번 문법 규칙은 잠시 접어두고 (3)번 문법규칙에 집중한다. 이제 다음 토큰인 c를 보면 (3)번 규칙에 부합한다. 그다음 토큰인 d를 보면 역시 (3)번 규칙에 부합할 뿐만 아니라 (3) 번 규칙을 완성했다. 따라서 bcd는 중간값 B로 대체되며 파서는 잠시 접어두었던 a뒤에 B가 있다고 생각한다. aB를 만족하는 규칙은 없다. 파서는 다음 입력값을 본다. e는 (6)번 규칙과 일치한다. 따라서 파서는 e를 E로 대체한다. 파서가 가지고 있는 값은 aBE가 되었다. 그런데 BE는 (4)번 규칙과 일치한다. 이제 BE는 C로 대체된다. 파서가 가지고 있는 값은 aC가 되었다. 이것은 (2)번 규칙에 따라 A로 대체된다. 이제 파서가 가지고 있는 값은 A이다. 더 이상의 입력값은 없다. 파서의 목표는 S에서 시작해서 abcde라는 문장을 만들어내는 것이었다. 이제 A로 시작하면서 S를 만족시킬 수 있는 문법 규칙은 (1)번밖에 없는데 D가 필요하다. 그런데 (5)번 규칙을 보면 D는 아무것도 없는 것을 표현한다. 따라서 파서는 A를 AD로 바꾸게 되면 이렇게 되면 (1)번 규칙과 일치해서 S로 대체된다. 이렇게 해서 만들어진 파싱 트리는 다음과 같다.
이 파싱 트리를 뒤집어 놓은 후에 변환 과정을 S에서부터 거꾸로 따지게 되면 아래의 그림과 같아진다.
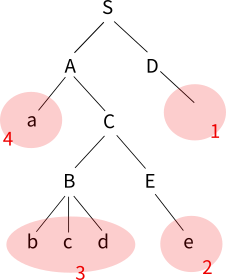
그림에서 붉은색 숫자가 변환 순서를 나타내는데 오른쪽 끝에서부터 차례로 변환이 진행되었음을 볼 수 있다. 따라서 이런 상향식 파싱은 LR 파싱이라고 부른다.
만약 LL 파싱을 사용한다면 어떻게 될까? LL 파싱은 문법 규칙들을 이리저리 조합하여 토큰의 나열에 들어 맞는 것이 나올 때까지 시도하는 하향식Top-down 방식이다. abcde라는 문장이 입력되면 파서는 (1)번 규칙에서부터 따지기 시작한다. S는 A와 D로 구성됨을 알았으므로 이제 A에 대한 규칙인 (2)를 따져본다. (2)번 규칙에 따르면 A는 a와 C로 구성된다. 입력 문장의 첫 토큰이 a이므로 여기에 부합한다. 이제 파서는 C에 대한 규칙을 따져본다. (4)번 규칙에 따르면 C는 B와 E로 구성된다. 일단 B를 먼저 고려한다. B는 bcd이다. 파서는 a 다음에 오는 토큰들을 확인한다. 다행히 b, c, d가 B의 규칙과 일치했다. 파서는 (3)번 규칙을 완성했으므로 (4번) 규칙으로 돌아가서 미뤄 놓았던 E번 규칙을 따져본다. (6)번 규칙에 따르면 E는 e이다. 문장에서 다음 토큰을 확인해보니 다행히 e이다. 따라서 (6)번 규칙이 완성되었고 자연스럽게 (4)번 규칙도 완성되었다. 그리고 (2)번 규칙까지 완성되었다. (1)번 규칙이 완성되려면 D가 필요하다. 그런데 D에 관한 규칙인 (5)번을 보니 아무것도 없는 것이다. 따라서 (1)번 규칙도 완성되었다. 이렇게 완성된 파싱 트리는 위와 동일하지만 변환 순서는 아래와 같이 다르다.
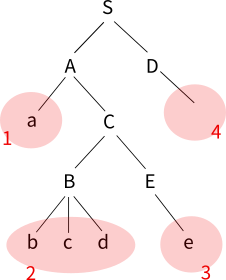
위의 예를 놓고 보면 LR 파싱이 LL 파싱보다 굳이 좋을 이유가 없어 보인다. 그 이유는 예로 사용한 문법이 너무 간단하기 때문이다. 실제 프로그래밍 언어에서는 다양한 경우의 수가 생긴다. 예를 들어 위의 문법에서 S에 대한 규칙이 여러 개 있다고 해보자. 그러면 LL 파싱은 그중 한 개를 임의로 선택해서 진행했다가 중간에 모순이 생기면 다시 처음으로 돌아와 다른 규칙으로 다시 진행해야 하는 비효율성을 가지고 있다. 그래서 현대의 프로그래밍 언어에서는 LR 파싱이 사용된다.
