튜링상 관련 업적
알고리듬 이론에 끊임없이 공헌했다. 여기에는 네트워크 흐름을 포함하여 조합 최적화 문제에 관한 효율적인 알고리듬 개발, 알고리듬 효율에 대한 직관적인 표현을 포함하는 다항 시간 계산 가능성, 그리고 특히 NP-완전 이론에 대한 기여가 포함된다. 그는, 주어진 문제가 NP-완전임을 증명하는 표준 방법론을 제안했다.
1985년 튜링상 선정 이유8
조합 최적화 문제
여행용 가방에는 번호 자물쇠가 달린 경우가 많다. 정해 놓은 원칙이 있는 것은 아닐 테지만 보통의 경우에는 세 자리 숫자 자물쇠가 국룰(?)이다. 자릿수가 많을수록 더 안전할 텐데 세 자리가 대세인 이유는 아마도 해제 번호값을 잊어먹었을 때를 위해서일 듯싶다. 한 달에 한 번씩 여행을 떠나는 사람이 아닌 이상은, 일 년에 많아야 한두 번 정도 가방을 열어 볼 텐데 우리의 정신 없는 일상은 그 세 자리 해제 번호값을 기억 속에서 사라지게 만들기 일쑤다. 그래서 모처럼 휴가를 맞아 들뜬 마음으로 가방을 열어 보려고 할 때면 해제 번호값이 기억나지 않을 때가 많고, 그러면 별수 없이 최악의 경우 총 1,000개의 숫자를 하나씩 확인해 보는 수밖에 없다. 만약 네 자리 번호 자물쇠라면 최악의 경우 10,000번을 시도해야 하는데 웬만한 인내력이 있지 않고서는 불가능하다고 보아야 한다.

이렇듯 어떤 답을 구하기 위해서 가능한 경우의 수를 꼼꼼히 따져봐야 하는 문제를 조합 최적화 문제combinatorial optimization problem이라고 부른다.# 조합 최적화 문제는 조합 폭발combinatorial explosion 현상을 동반하곤 한다. 문제의 크기가 커지면 답을 구하는 시간이 급격히 증가하는 것을 말한다. 위의 여행용 번호키가 여기에 해당한다. 두 자리 번호키는 (최악의 경우) 100번만 시도하면 해제 번호값을 알아낼 수 있지만 세 자리 번호키에서는 1,000번, 네 자리 번호키에서는 10,000번의 시도가 필요하다. 자릿수가 한자리 늘 때마다 시도 횟수가 급격히 증가한다.
놀랍게도 우리의 일상에는 조합 최적화 문제가 많다. 대표적인 것으로 통 채우기 문제bin packing problem와 외판원 문제traveling salesman problem가 있다. 먼저 통 채우기 문제를 보자. 어떤 통bin이 있는데 여기에 크기가 다른 여러 물건을 담아야 한다. 최대한 물건을 많이 담으려면 어떻게 해야 할까? 가장 큰 것부터 담을까? 아니면 가장 작은 것부터 담을까? 안타깝게도 정답은 없다. 사실 우리는 이미 생활 속에서 이를 터득했다. 이삿짐을 쌀 때 이삿짐 박스의 개수를 최소로 하는 방법은 무엇일까? 정답은, “이렇게도 해보고 저렇게도 해봐서 제일 괜찮은 걸 찾는다”이다.
외판원 문제
리처드 카프는 외판원 문제에 꽂혀 살았다. 외판원 문제란, 여러 도시들을 가장 최소의 비용으로 방문하는 경로를 찾는 것이다. 여기서 비용은 거리일 수도 있고, 교통 요금일 수도 있다. 이 문제도 답을 구하려면 ‘이렇게도 해보고 저렇게도 해보는 수’밖에 없다.** 하지만 막무가내식으로 모든 경우의 수를 다해보는 것은 너무 짜증 나는 일이다. 그래서 조금이라도 경우의 수를 줄이려는 노력이 이루어졌다.
리처드 카프가 처음 이 문제에 도전했던 1960년대 초반에는, 도시의 개수가 50개를 넘어서면 당시의 가장 좋은 알고리듬으로도 시간이 너무 오래 걸려서 현실적으로 사용할 수 없었다. IBM의 동료와 함께 이 문제에 도전한 카프는 여러 방법을 동원했다. 처음에는 동적 계획법dynamic programming 을 적용했으나 도시의 개수가 16개를 넘어가면 무용지물이었다. 그다음에는 국지적 탐색local search 방법을 사용해보았는 데 큰 효과는 보지 못했다.†† 그래서 다음으로 시도한 것이 분기 한정법branch-and-bound 이었다.
분기 한정법은 탐색 트리를 사용한다. 탐색 트리search tree란, 탐색의 모든 가능한 경우의 수를 트리 형태로 만든 것이다. 아래의 그림은 한국에서 7개의 도시를 방문하는 예이다. 외판원은 서울에서 출발하여 6개의 도시를 방문한 후 다시 서울로 돌아와야 한다.

이 문제의 답을 구하기 위해 탐색 크리를 만들면 다음과 같다.
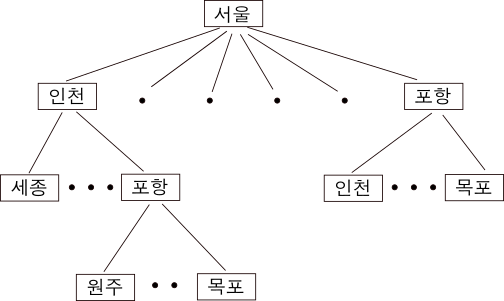
서울에서 시작했을 때 그다음에 방문할 수 있는 도시는 6개가 있다. 이것들이 트리의 두 번째 레벨에 해당한다. 만약 어떤 도시를 선택했다면 그다음에 방문할 수 있는 도시는 5개가 있다. 이것들이 트리의 세 번째 레벨이다. 다시 그 도시에서 그다음에 방문할 수 있는 도시는 4개이다. 이것들이 트리의 네 번째 레벨이다. 이런 식으로 트리를 계속 그려나가면 결국 가능한 모든 경우의 수를 트리 형태로 그리는 셈이 된다.
그렇다면 탐색 트리에서 정답은 어떻게 찾을 수 있을까? 가장 위에 있는 서울에서 시작해서 모든 가능한 경로를 하나씩 따져보아야 할 것이다. 그런데 만약 어떤 노드 이하는 따져볼 필요가 없어진다면 우리는 작업의 양을 줄일 수 있게 된다.
카프의 분기 한정법은 탐색 트리의 각 노드에 ‘하한 비용lower bound‘이라는 것을 계산해 놓는다. 위의 예에서 ‘하한 비용’은 해당 노드의 밑에 딸려 있는 도시들을 방문할 때의 최소 거리가 될 것이다. 자, 이제 하한 비용이 어떻게 쓰이는지 들여다보자. ‘서울’ 다음에 ‘인천’을 선택했고, 그다음에는 ‘세종’을 선택하는 식으로 쭉 트리를 따라 내려가면 맨 밑에 있는 어떤 노드에 도달하게 될 것이다. 이렇게 되면 하나의 방문 경로가 완성되는 것이고 우리는 총거리를 구할 수 있다. 이제 다시 맨 위로 올라와서 ‘서울’ 다음에 ‘인천’을 선택하고 그다음에는 ‘포항’을 선택했다고 하자. 우리는 ‘서울’-‘인천’-‘포항’의 거리를 할 수 있다. 그런데 여기에 ‘포항’ 노드의 하한 비용을 더했더니 이전에 ‘서울’-‘인천’-‘세종’ 경로를 따랐을 때의 총거리보다 더 크다면 우리는 굳이 ‘포항’ 노드 아래까지 훑어볼 이유가 없어진다.
이런 기법을 적용한 카프의 방법은 도시의 개수가 65개일 때까지 처리할 수 있었다.
NP-완전
NP-완전complete의 개념을 처음 발견한 사람은 스티븐 쿡이었지만, 이를 널리 알린 공은 리처드 카프에게 있다. 사실 스티븐 쿡은 자신이 발견한 개념에 특별히 이름을 붙이지 않았다. NP-완전이라는 이름을 붙인 이가 리처드 카프이다. 1971년에 스티븐 쿡이 <정리 증명 절차의 복잡성6>이라는 논문을 발표했고, 이 논문을 읽은 카프는 NP-완전 개념을 더 많은 사례에 적용해 보고 그 결과를 <조합 문제에 있는 환원성>7이라는 제목으로 발표했다.
NP-완전은 하나의 문제 부류이다. 어떤 문제가 NP-완전 부류에 해당하려면 아래의 조건을 만족해야 한다.
1. 이 문제가 NP에 해당하면서 동시에,
2. NP에 있는 모든 문제들이 이 문제로 환원가능해야 한다.환원 가능reducible하다는 말의 의미는, ‘대신해 줄 수 있다’는 것이다. 예를 들어 A라는 문제가 주어졌을 때, A가 B로 환원 가능하다면 우리는 B라는 문제를 풀면 된다. 왜냐하면 B 문제가 A 문제를 대신해줄 수 있기 때문이다. B 문제의 답으로부터 A 문제의 답을 구하는 것은 다항 시간 내에 할 수 있다.
따라서 위의 설명을 종합해 본다면 NP-완전 부류에 속한 문제를 풀게 되면 결국 NP에 있는 모든 문제들의 답을 구할 수 있다는 것이다.
아직 설명하지 않은 것이 있다. 그렇다면 NP란 무엇인가? NP에 대한 정의는 다음과 같다.
NP는 비결정적 튜링 기계nondeterministic Turing machine에 의해 다항 시간 내에 풀 수 있는 문제이다.7NP의 상대적인 개념으로 P라는 부류가 있다. P에 대한 정의는 다음과 같다.
P는 결정적 튜링 기계deterministic Turing machine에 의해 다항 시간 내에 풀 수 있는 문제이다.7따라서 P와 NP의 차이점은 결정적 튜링 기계를 사용하느냐 아니면 비결정적 튜링 기계를 사용하느냐에 있다. 이것은 현실 세계에서 엄청난 차이를 만들어 낸다. 결정적 튜링 기계는 항상 다음 단계가 하나로 정해져 있는 기계이다. 이에 비해 비결정적 튜링 기계는 다음 단계가 여러 개일 수 있다. 현실의 물리적 세계에서는 오직 하나의 단계만 선택할 수 있다. 따라서 결정적 튜링 기계에 의해 다항 시간이 걸린다고 한다면 그것은 현실 세계에서도 다항 시간이 걸린다. 하지만 비결정적 튜링 기계에 의해 다항 시간이 걸린다고 해도 현실 세계에서는 여러 경우의 수를 어떻게 처리하느냐에 따라 다항 시간이 걸릴 수도 있고 훨씬 더 많은 시간이 걸릴 수도 있다.
P와 NP를 다른 식으로 정의하기도 해서 여기에 소개하고자 한다. 튜링상 수상 강연에서 카프는 다음과 같이 설명하고 있다.
덜 딱딱하게 설명한다면 P라는 부류class 에 속한 문제들은 다항 시간 내에 답을 구할 수 있는 것들입니다… NP라는 부류에 속한 문제들은 (어떤 답이 후보로 주어졌을 때) 다항 시간 내에 답이 맞는지 틀리는지를 검사할 수 있는 것들입니다.1
따라서 P에 속하는 문제들은 모두 NP에 속하지만 NP에 속한다고 해서 P에 속한다고는 말할 수 없다.
여기서 그 유명한 P=NP? 문제가 등장한다. NP에 해당하는 문제의 답을, 현실 세계에서 다항 시간 내에 구하기는 경험적으로나 심정적으로나 어려워 보인다. 하지만 아직까지 명백하게 그것을 증명해 내지는 못했다. 만약 누군가 NP-완전 문제 중 어느 하나에 대해 다항 시간 내에 답을 구하는 알고리듬을 찾아낸다면 이제 모든 NP 문제는 P에 해당하게 된다. 하지만 아직 그 누구도 그런 알고리듬을 찾아내지 못했으며, 동시에 그런 알고리듬을 찾아내기 불가능함을 증명한 이도 없어서 미해결 문제로 남아 있다.
카프가 NP-완전 개념에 눈길을 주게 된 이유는 복합적이다. 일단은 카프와 쿡이 캘리포니아 대학교 버클리에서 몇 년 동안 함께 일했다는 점이 작용했을 가능성이 있다. 아무래도 아는 사이였으니 카프가 반가운 마음으로 논문을 일찍 읽지 않았을까? 그런데 놀랍게도 쿡은 NP-완전이라는 개념을 버클리에서는 전혀 드러내 보인 적이 없었다고 한다. 그래서 카프도 논문을 통해서 처음 이 개념을 접했다고 한다.
그렇다고 치더라도 논문을 읽은 이가 한둘이 아닐 터인데 특별히 카프가 남들보다 먼저 그 가치를 알아챈 데에는 또 다른 이유가 있다. 그는 튜링상 수상 강연에서 이에 대해 자세히 언급했다. 먼저 카프의 논문 제목에서 볼 수 있듯이 그는 조합 문제와 환원성reducibility 두 가지에 주목했다. 조합 문제는 그가 IBM 시절부터 계속 연구 주제로 삼고 있었던 것이었고 다항 시간 알고리듬을 찾기 어렵다는 점에서 NP-완전의 부류에 포함될 가능성이 높았다.
또한, 다항 시간이란 개념을 카프는 일찍 접했다. 그는 IBM 시절에 잭 에드먼즈와 함께 네트워크 흐름network flow 알고리듬을 같이 연구한 적이 있었는데, 이때 에드먼즈는 알고리듬의 효율을 정량적으로 평가하기 위해서 수행 시간이 입력 데이터 크기를 변수로 하는 함수로 표현되어야 하고, 그 함수가 다항 함수이면 알고리듬의 효율이 ‘좋다’고 말할 수 있다는 견해를 보였다.1
그리고 카프가 하버드 대학교에서 공부하던 시절에 그가 가장 두각을 나타냈던 과목의 담당 교수였던 하틀리 로저스 교수는 환원성reducibility을 가르쳤었다. 스티븐 쿡의 논문에서 핵심 개념이 환원성이었으므로 카프는 그 논문을 빠르게 이해했을 것이다.
그래서 카프는 환원성을 이용해서, 자신이 관심을 가지고 있던 조합 문제를 포함하여 21개의 문제가 NP-완전에 해당함을 증명했다. 이 21개의 문제에는 외판원 문제를 포함하여 배낭싸기knapsack, 덮개covering, 부합matching, 분할partition 등의 문제가 포함되어 있다.
조합 문제에 대한 확률적 접근
NP-완전에 해당하는 문제들은 입력 데이터의 크기가 커지면 답을 구하는 시간이 너무 오래 걸려서 포기할 수밖에 없다. 그렇다면 그냥 손 놓고 있어야만 할까? 그럴 수는 없는 일이다. 뭔가 차선책을 찾아야 한다.
1972년에 NP-완전을 깔끔하게 정리한 그는 갑자기 맡게 된 대학 보직 때문에 몇 년간 연구에서 손을 뗐다. 1975년에 다시 연구할 시간을 가지게 된 그는 바로, 이 차선책을 고민하기 시작했다. 그가 선택한 방법은 최대한 정답에 가까운 답을 구해보자는 것이었다. 그래서 그는 입력 데이터가 어떤 확률적 분포를 가지고 있다고 가정해 보았다. 위험한 가정이었다. 왜냐하면 실제로 현실 세계에서 입력 데이터가 그런 확률적 분포를 가질지는 확실치 않았기 때문이었다. 카프는 정답에 가까운 답이 높은 확률로 나오기를 기대했다.
외판원 문제에서 외판원이 방문해야 할 도시들이 물리적으로 어떻게 위치하고 있을지는 사실 알 수 없다. 그때그때 달라진다고 보아야 옳을 것이다. 그런데 카프는 이 도시들의 위치가 서로에 독립적이면서 정규 분포를 따른다고 가정했다. 그런 후에 전체 지역을 일정 크기로 분할한 후 각 지역별로 그 안에 있는 도시들만 대상으로 외판원 알고리듬을 각각 수행했다. 그런 후에 이 지역별 결과를 다시 하나로 묶어 주는 알고리듬을 수행했다.
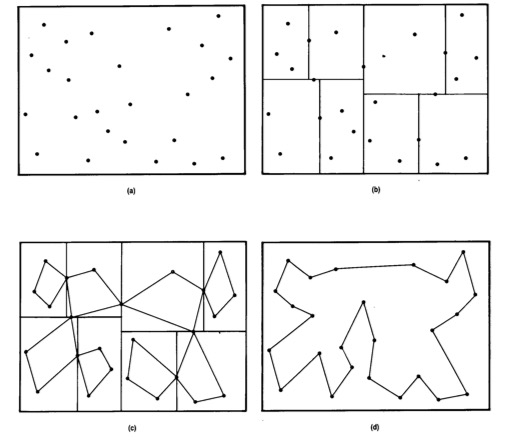
결과는 기대 이상이었다. 도시의 개수가 많을수록 좋은 결과가 나왔다. 그 이유는 데이터의 양이 많아질수록 점점 정규 분포의 특성을 따를 가능성이 높아진다는 확률적 특성 때문이었다.

답글 남기기