튜링상 관련 업적
인공지능에 관한 연구에서 상당한 인정을 받음.
1971년 튜링상 선정 이유2
1971년 튜링상은 다른 해와 다른 특이한 점을 가지고 있다. 먼저 선정 이유가 모호하게 표현되어 있다. 다른 해에는 수상자의 특정 연구 주제나 논문 등을 구체적으로 적시하였으나 유독 1971년에는 그렇지 않았다.
거기에 더해서 수상 강연도 정식으로 발표되지 않았다. 그 이전까지만 해도 ACM(미국 컴퓨터 학회)의 발행물을 통해서 하나의 자료로 공개했으나 1971년은 그렇지 않았다. 당시의 수상 강연을 녹화해 놓은 동영상이 있는 것도 아니므로 그 이유를 정확히 알기는 어렵다. 하지만 그 단서를 찾을 수는 있다. 1986년에 존 매카시는 1971년의 강연을 다시 정리하여 발표했다. 그 서두를 보면 이렇게 적고 있다.
나의 1971년 튜링상 수상 강연 제목은 ‘인공지능에서의 보편성’이었다. 이 주제는 좀 과한 욕심으로 드러났다. 왜냐하면 주제에 대한 생각을 만족스럽게 글로 옮길 수가 없었기 때문이었다. 뭔가 새로운 것을 시도하기보다는 그때까지 내가 했던 일을 정리하는 편이 낫지 않았나 싶다. 하지만 그것은 그 당시 내 스타일이 아니었다.1
1971년이면 존 매카시가 스탠퍼드 대학교의 정교수가 된 지 거의 10년이 된 시점이었다. 이미 1950년대 말과 60년대 초에 그는 인공지능 연구는 물론이고 프로그래밍 언어와 시분할 시스템에서 큰 족적을 남긴 상태였다. 그러므로 굳이 구체적으로 선정 이유를 밝히지 않더라도 여기에 토를 다는 사람은 없었을 것이다.
사실 알고 보면 프로그래밍 언어와 시분할 시스템에 대한 그의 기여 또한, 인공지능에 대한 열정에서 파생되었다. 인공지능을 위한 언어를 고민하다가 리스프 언어를 개발했고, 보다 편하게 인공지능을 개발하기 위한 환경을 고민하다가 시분할 시스템을 제안했다.
다트머스 인공지능 워크샵

1955년에 IBM은 과학계산용 컴퓨터인 704 모델을 미국 동부에 있는 대학들에게 연구 및 교육용으로 제공할 계획을 세웠다. MIT를 포함하여 뉴잉글랜드 지역의 대학교들을 대상으로 했는데 여기에는 다트머스 대학교도 포함되었다. IBM 연구소에 있던 나다니엘 로체스터는 대학교를 돌아다니면서 담당자를 물색했고 다트머스 대학교에서 매카시를 만나게 된다. 매카시는 로체스터의 초청으로 1955년 여름 방학 동안 IBM 연구소에서 일했고 그가 가지고 있던 인공지능에 대한 열망을 로체스터에게 전염시켰다.4
이때 매카시와 로체스터는 다음 해 여름에 다트머스 대학교에서 워크샵을 열어 보자는데 의기투합하면서 클로드 섀넌과 마빈 민스키를 끌어들였다. 1955년 8월에 매카시는 ‘인공지능에 관한 여름 연구 프로젝트’라는 이름의 제안서를 작성해서 록펠러 재단에 제출했다.5
다트머스 워크샵에 참석한 이는 11명 정도에 불과하다. 그리고 모두 한자리에 모인 기간은 2주 정도에 불과하다. 아직 제대로 된 컴퓨터도 없던 시절이었으므로 이들의 목적은 연구 방향을 모색하는 데 초점이 맞추어져 있었다. 따라서 이 워크샵이 특별한 결과물을 남기지는 못했다.
하지만 이 워크샵에서 앨런 뉴얼과 허버트 사이먼이 Logic Theorist프로그램을 처음 공개했고, 참석자들은 컴퓨터를 사용한 인공지능의 가능성을 엿보았다.
리스프 언어
세상에는 많은 프로그래밍 언어들이 있다. 그중 가장 오랜 역사를 자랑하는 언어 중 하나가 리스프LISP이다. 리스프는 LISt Processor를 줄인 표현이다. 그 표현 그대로 해석하자면 ‘리스트list를 처리하는 언어’이다. 구체적으로 살펴보기에 앞서서 리스프 언어가 만들어진 시대적 배경을 한번 생각해 보겠다.
리스프 언어를 실제로 만들기 시작한 때는 1958년이다. 1958년이면 아직도 극소수의 사람들만 컴퓨터에 접근할 수 있던 시기이다. 아울러 고급 프로그래밍 언어로는 포트란 언어가 유일했다. 고급 프로그래밍 언어에 대한 시도가 지속적으로 이루어져 오기는 했으나 실제로 현장에서 쓸만한 것은 1957년에 나온 포트란밖에 없었다. 알골이라는 고급 언어에 대한 논의가 시작된 시기이기도 하다.
그렇다면 인공지능 연구자들은 어떤 언어로 프로그램을 작성했을까? 몇 년 앞서서 개발되어 큰 반향을 일으켰던 Logic Theorist라는 프로그램은 어셈블리어 언어 수준에서 개발되었다. 따라서 인공지능에 적합한 고급 프로그래밍 언어는 전무했다고 보아도 무방하다.
리스프 언어를 만들기 된 동기
존 매카시가 새로운 언어를 만들어야겠다는 결심을 굳힌 때는 1958년 여름이었다. 당시 그는 다트머스 대학에서 MIT로 자리를 옮기기 직전에 잠시 IBM에서 자문을 하며 일하고 있었다. 그가 했던 자문은 포트란 언어를 이용한 인공지능 개발이었다.
좀 더 구체적으로 말하자면, 1956년에 다트머스 인공지능 워크샵에 참석하기도 했던 나다니엘 로체스터는 포트란 언어를 이용해서 수학 공식을 증명하는 프로그램을 만들고 있었다. 이 프로그램을 위해서는 포트란 언어에 리스트 구조 지원 기능을 추가해야 했고, 그렇게 해서 만들어진 언어가 FLPL(Fortran List Processing Language)였다. 이 일에 매카시는 자문 역할을 했다.7
동시에 매카시는 자신만의 연구를 진행하고 있었다. 그는 미분 작업을 프로그램으로 구현하고 있었다. 다항식을 미분하는 과정은 여러 기법이 동원되는 데 변수들의 곱셈으로 이루어진 항을 미분하면 각 변수를 미분하는 작업이 필요하다.8 예를 들면 다음과 같은 식이다.

이제 이것을 프로그래밍 언어의 함수로 구현한다고 가정하고 그 함수의 이름을 diff라고 해보자. 그러면 위의 풀이는 아래와 같이 표현된다.¶
diff(xy) {
return diff(x) * y + x * diff(y);
}이 함수에는 독특한 특징이 있다. diff라는 함수를 수행하는 과정에서 다시 diff라는 동일한 함수를 호출하게 된다. 이런 것을 재귀적 호출recursion이라고 부른다.
매카시는 여기서 벽에 부딪혔다. 포트란은 언어의 구조상 재귀적 호출을 허용하지 않았다.7 재귀적 호출이 정상적으로 처리되기 위해서는 스택stack이라는 메모리 관리 기법이 필요했다.# 결국 매카시는 FLPL을 포기하고 직접 프로그래밍 언어를 만들기로 결심했다.
리스프 언어의 기술적 배경
리스프 언어는 어느 한순간에 고민해서 ‘번쩍’하고 태어난 언어가 아니다. 리스프가 가진 많은 특징들은 상당한 시간을 거치면서 차근차근 형성되었다.
리스프가 전체적으로 깔끔해 보이기 때문에 처음부터 그렇게 계획된 것으로 생각하는 분들도 계실지 모르겠습니다. 하지만 사실은 그렇지 않습니다. 조금씩 커나가다가 어느 순간 일종의 지역적 최대치, 어쩌면 지역적 최소치로 턱 하니 만들어졌습니다.8
리스트 구조
리스프 언어의 특징으로는 먼저 리스트 구조list structure가 있다. 흥미로운 점은 언어에서 다루는 데이터의 구조만 리스트인 것이 아니라 프로그램 자체의 구조도 리스트라는 것이다. 리스트 구조를 선택하게 된 배경에는 1956년의 다트머스 인공지능 워크샵이 있다.
1956년 워크샵의 발표자 중에는 Logic Theorist를 개발했던 뉴얼과 사이먼이 있었다. 그들은 자체적으로 IPL이라는 언어를 만들었는데 어셈블리어에 가까운 언어였다. IPL에는 독특한 특징이 몇 가지 있었는데, 그중 하나가 데이터를 리스트 구조로 다룬다는 점이었다.
리스트 구조의 장점은 대량의 데이터를 동적으로 다룰 수 있다는 것이다. 즉 프로그램에서 다루는 데이터의 개수가 실행과정에서 동적으로 바뀔 수 있다. 매카시는 IPL의 리스트 구조를 인상적으로 받아들였다.
당시에 IBM은 다트머스 대학에게 IBM 704 모델을 사용할 수 있도록 해주었다. 그래서 매카시는 이 컴퓨터를 사용할 생각으로 IBM 704의 기계어 명령어 구조를 반영하여 리스트 구조를 설계했다.7 IBM 704의 명령어는 36비트였는데 특정 명령어의 경우, 네 부분으로 나뉘었다.** address 부(15비트), decrement 부(15비트), prefix 부(3비트), tag 부(3비트)였다. address 부와 decrement 부에 저장된 값은 그 자체가 의미 있는 숫자일 수도 있었고, 아니면 메모리 주소일 수도 있었다. 따라서 다음과 같은 이진 트리 형태의 리스트 구조를 만들 수 있다.
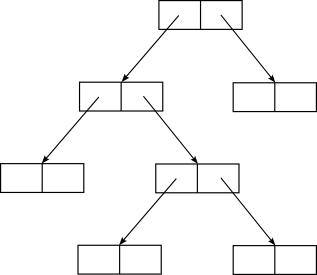
매카시는 이 기계어 명령어 구조를 활용하는 고급 언어 명령어를 궁리했고 그래서 3가지 명령어가 만들어졌다. 첫 번째는 car(Contents of the Address part of Register)이다. 이는 말 그대로 address 부가 가리키는 곳의 값을 뽑아내는 명령어이다. 두 번째는 cdr(Contents of the Decrement part of Register)이다. 레지스터의 decrement 부가 가리키는 곳의 값을 뽑아내는 명령어이다. cdr 명령어로 얻어낸 36비트는 nil(끝을 의미하는 특수값)이 아닌 이상, 현재 주어진 리스트에서 첫 리스트 원소element를 제외한 나머지 리스트 원소들로 구성된 리스트를 나타낸다. 마지막 명령어는 cons 명령어이다. 그는 IBM의 FLPL 자문을 하면서 cons 명령어를 구체화시켰는데, 이것은 인자로 주어진 두 개의 리스트를 결합하고 그렇게 해서 만들어진 리스트는 메모리에서 사용하지 않고 있는 주소를 할당받아 그곳에 저장한다.
이렇게 해서 리스프의 가장 기본적인 명령어인 car, cdr, cons 만들어졌다. 하지만 아직 이때까지만 해도 매카시는 별도의 언어를 만들기보다는 포트란에서 이를 구현할 생각이었다.
조건문
프로그래밍 언어에서 조건문은 빠질 수가 없는 명령어이다. 현대의 프로그래밍 언어라면 사용하는 단어에 차이가 있을지언정 다음과 같은 구조의 명령어를 반드시 포함하고 있다.
if ... then ... else ...이런 형태의 조건문을 처음 제안한 이가 존 매카시이다. 그는 포트란 언어로 체스 프로그램을 만들다가 너무 불편함을 느꼈다고 한다.7 포트란의 조건문에서는, 조건을 따지기 위한 계산을 한 후에 그 값이 0보다 작을 때, 0일 때, 0보다 클 때, 총 3가지 경우를 따지게 되어 있었다. 매카시는 이렇게 작성한 프로그램이 복잡해질 뿐만 아니라 직관적이지 않다고 보고, 참/거짓을 따지는 조건문을 제안했다. 그리고 이것을 리스프 언어에 반영했다.
재귀적 호출
매카시가 포트란을 포기하고 새로운 프로그래밍 언어를 만들어야겠다고 마음먹은 이유가 바로 재귀적 호출 때문이었다. 재귀적 호출이란, 어떤 함수를 처리하는 중에 다시 같은 함수를 호출하는 것을 말한다. 1956년에 매카시는 IPL이 재귀적 호출을 지원한다는 사실을 알게 되었다. 재귀적 호출이 구현되기 위해서는 함수가 호출될 때마다 그 함수의 임시 계산 결과를 저장하기 위한 메모리 공간을 할당해주어야 하는데 스택이라는 형태로 구현되었다. 그런데 IPL은 스택 관리를 프로그래머가 직접 응용 프로그램 내에 작성해주어야 했다. 매카시는 리스프 언어에서 스택이 자동으로 관리가 되도록 구현했다.
람다 대수
리스프 언어는 함수형 프로그래밍 언어이다. 함수형 프로그래밍 언어란, 프로그램의 흐름이 함수 호출들로 구성되어 있으며 함수의 호출은 프로그램 내의 어떤 상태로 변화시키지 않고 단지 그 결과값만 사용된다.
그런데 리스프는 함수를 호출할 때 인자값으로 다른 함수를 사용할 수 있다.†† 문제는, 인자값으로 사용되는 함수도 자체적으로 인자argument를 가지고 있을 수 있다는 점이다. 따라서 그 함수 인자를 구별해줄 방법이 필요하다. 그것을 위해 람다 대수lambda calculus 방법이 도입되었다.
가비지 컬렉션
리스트 구조를 사용하여 동적으로 메모리를 사용하게 되면 더 이상 사용되지 않는 메모리를 관리해야 할 필요성이 생긴다. IBM 704 모델을 예로 들어보면, 모든 리스트 데이터들은 36비트 단위로 구성되어 관리된다. 만약 cons 명령에 의해 새로운 리스트가 만들어져야 할 상황이 되면, 메모리에서 사용되고 있지 않은 주소 공간을 할당받아 새로운 리스트용으로 사용한다. 그런데 이렇게 만들어진 리스트에 대해 car명령으로 첫 리스트 원소만 사용하고 끝나면 나머지 리스트 원소들이 저장된 메모리 공간은 버려진 채로 남게 되는데 이것을 재사용할 방법이 필요하다.
IPL에서는 이렇게 쓰고 버려진 공간을 재사용하기 위한 코드를 직접 응용 프로그램에 포함했다. 매카시는 그것이 너무 불편하다고 보고 자동으로 처리하는 방식을 고안해냈는데 이것을 가비지 컬렉션garbage collection이라고 불렀다.
먼저 메모리 공간 내에서 리스프 프로그램이 원할 때 사용할 수 있는 여유 공간 목록을 구성해 놓는다. 리스프 프로그램이 수행되면서 메모리가 추가로 필요하면 이 여유 공간에서 할당해준다. 만약 여유 공간이 부족해지면 가비지 컬렉션이 시작된다. 이를 위해서 현재 프로그램에서 접근 중인 리스트들을 추적하여 해당되는 36비트 데이터마다 ‘사용 중’이라는 표시를 하게 되고 그런 후에 메모리 공간 내에서 ‘사용 중’ 표시가 되어 있지 않은 36비트 데이터를 찾아서 모두 여유 공간 목록으로 지정해준다.
인터프리터
1958년 여름에 리스프 언어를 개발하기로 마음먹었지만 매카시에게는 이를 진행할 인력도 자원도 없었다. 반전의 계기는 1958년 가을에 그가 MIT에서 인공지능 연구소를 만들면서 생겼다.
우리(매카시와 민스키)는 복도에서 (전자연구소 소장이던) 제리 위즈너와 마주쳤습니다. 그에게 이렇게 말했습니다. “우리는 인공지능 연구소를 원합니다.” 그는 묻더군요. “그래서 뭐가 필요한데?” 내가 답했습니다. “방 하나랑, 키펀칭 기계 하나, 그리고 프로그래머 두 명만 있으면 해요.” 그러자 그는 “대학원생 여섯 명은 어때? 전자연구소가 수학과 대학원생 여섯 명을 떠맡았는데 걔네들한테 뭘 시켜야 할지 모르겠어”라고 말했습니다.4
갑자기 인력이 늘어나자 매카시는 그가 설계한 리스프 언어를 위한 컴파일러를 만들 기대에 부풀었다. 하지만 IBM이 포트란 컴파일러 개발에 투입한 인력과 비용을 듣고는 크게 낙담했다. 도저히 감당이 되지 않을 정도로 컸기 때문이었다. 그래서 그는 일단 손으로 컴파일해보면서 리스프 언어를 다듬는 쪽으로 방향을 틀었다.
이 과정에서 eval이라는 명령어가 추가되었다. 주어진 리스트 구조의 값을 계산하는 명령어였다. 그런데 이 명령어를 설명 들은 스티브 러셀Steve Russell‡‡이 그 명령어를 구현해보겠다고 나섰다.
러셀이 그걸 보더니 “내가 그걸 프로그램으로 구현해보죠. 그러면 리스프용 인터프리터를 갖게 되는 거 아닌가요?”라고 말했습니다. 그러더니 정말로 만들어내더군요. 약간 놀라웠습니다. 아무튼 그렇게 해서 인터프리터가 갑자기 등장했습니다.8
최초의 리스프 컴파일러는 1962년에 개발되었다. 리스프 컴파일러는 리스프 언어로 만들어졌다. 자신의 컴파일러를 자신의 언어로 만든 최초의 사례였다.

답글 남기기