스택
스택stack은 컴퓨터 시스템에서 소프트웨어적으로 메모리를 관리하는 기법 중 하나이다. 사전적인 의미로는 ‘뭔가가 쌓여 있는 것’을 말한다. 어떤 물건들이 차곡차곡 쌓여 있다고 가정해보자. 이 물건들을 사용하려면 중간에 끼어 있는 것을 잡아 빼기보다는 맨 위에 놓인 것부터 차례대로 사용하는 것이 상식적이다. 바로 그런 특징을 가진 메모리 관리 기법이기 때문에 ‘스택’이라는 이름이 붙었다.
스택은 재귀적 호출을 구현하는 방법으로 제안되었다.5 재귀적 호출에 대한 아이디어는 이미 미국에서 Logic Theorist‡‡ 프로그램 속에 구현되었다. 재귀적 호출은 어떤 함수가 자신을 호출하는 것을 말한다. 대표적인 사례가 미분 함수이다.§§
재귀적 호출을 프로그래밍으로 구현하려면 곤란한 상황에 부닥친다. 내부 변수, 인자 전달, 복귀 주소 등을 처리하기가 곤란해진다. 지금은 당연하게 여겨질 수 있지만, 이때는 1950년대 후반이었음을 상기하자. 아직 변변한 컴파일러가 없어서 대다수 프로그래머들은 기계어나 어셈블리어로 프로그램을 작성하고 있었다. 대부분의 프로그램이 수학 계산용이었으므로 함수 혹은 서브루틴들은 수학 계산을 도와주기 위해 작성되었다. 대표적인 것으로, 절대값 계산을 들 수 있겠다.
function abs (x) {
var result;
if (x > 0) result = x;
else result = x * -1;
return result;
}1950년대 말에는 위와 같은 코드는 실제로 사용할 수 없었다. 왜냐하면 아직 고급 언어가 존재하지 않았기 때문이다. 위와 같은 구조의 프로그램이 가능해진 것은 알골 언어가 발표된 후부터이다. 1950년대 말에는 일단 순서도flow chart를 그린 후에 거기에 맞춰 기계어로 프로그래밍했다.
아무튼 개념적으로는 위와 같이 함수가 만들어지는데, 이 함수는 x라는 인자를 받아서 계산한 후 그 결과를 result라는 변수에 저장했다가 리턴값으로 사용한다. x와 result는 변수이므로 메모리의 특정 위치에 저장되어 사용된다. 그런데 x는 이 함수를 호출한 코드에서 값을 지정해주어야 하므로, 이 함수를 호출한 코드와 이 함수 둘 다 x가 위치한 메모리 번지를 알고 있어야 한다. result도 마찬가지이다. result의 값을 결정하는 것은 이 함수이지만 거기에 저장된 값을 호출한 코드 쪽에서 읽어가려면 역시 result 변수가 위치한 메모리 번지를 양쪽이 모두 알고 있어야 한다. 그래서 초창기에는 함수를 호출할 때 인자값이 저장되는 메모리 번지와 리턴값이 저장되는 메모리 번지를 미리 약속하여 정해놓았다. 한편, 함수가 수행을 끝낸 후에는 자신을 호출했던 코드 쪽으로 복귀해야 하는데 그 위치를 기억하고 있어야 한다. 따라서 함수를 호출한 코드의 번지를 기록해 놓는 메모리 번지도 미리 약속하여 정해놓았다.
function factorial (x) {
var result;
if (x > 1) result = factorial (x-1) * x;
else result = 1;
return result;
}자. 이제 재귀적 호출이 들어 있는 함수를 살펴보자. x! 값을 구하는 함수이다. x! = x * (x-1)!를 응용하여 작성한 함수이다. (물론 다르게 작성할 수도 있지만 재귀적 호출을 설명하기 위해 일부러 이렇게 구현했다.) 이 경우도 앞에서와 마찬가지로 이 함수를 호출한 코드와 함수 내부에서 모두 x와 result에 접근할 수 있어야 한다.
그런데 앞의 사례에서처럼 인자값과 리턴값의 저장 위치가 고정이 되어 있다고 해보자. factorial(3)이라고 함수를 호출하려면 일단 현재의 위치를 복귀 번지용 메모리 위치에 저장하고, 인자값 메모리 위치에 3을 저장한 후에 factorial 함수 코드로 이동해야 한다. 그러면 factorial 함수는 인자값 위치를 읽어서 1과 비교하는데 1보다 크므로 factorial(2)를 호출한다. 이때 인자값 위치에 2를 저장하게 된다면 이전에 들어 있는 3을 덮어쓰게 되며 복귀 번지용 메모리 위치도 덮어쓰게 된다. 다시 factorial 함수는 인자값 위치를 읽어서 1과 비교하고 1보다 크므로 facotrial(1)을 호출한다. 다시 factorial 함수가 처음부터 실행되면서 인자값 위치를 읽어서 1과 비교하는데 1과 같으므로 리턴값 메모리 위치에 1을 저장하고 이제 호출한 코드로 복귀하게 된다. 복귀할 위치는 복귀 번지용 메모리 위치를 읽어서 알 수 있다. 여기에 저장된 위치는 factorial(2)를 실행하는 중에 factorial(1)을 호출한 위치이다. 이곳으로 복귀하면 나머지 작업인 * x를 해야 하는데 여기서 문제가 발생한다. 개념적으로는 x의 값이 2이어야 하지만 아까 factorial(1)을 호출하면서 x에 해당하는 메모리 번지의 값이 1로 덮어 쓰여졌기 때문이다. 따라서 결국 factorial(1) * 1 이라는 계산이 이루어져서 잘못된 결과가 만들어진다.
또 다른 문제도 있다. factorial(1)에서 factorial(2)로 복귀하고 다시 factorial(3)으로 복귀한 후에는 원래 처음 이 함수를 호출한 코드로 복귀해야 한다. 하지만 이미 복귀 번지용 메모리 위치의 내용이 덮어 쓰여졌으므로 계속 factorial 함수 안으로 복귀하게 된다. 결과적으로 이 프로그램은 계산도 틀렸을 뿐더러 프로그램이 종료하지 않고 멈춰 있는 것처럼 보일 것이다.
이런 문제 때문에 재귀적 호출을 위해서는 새로운 메모리 관리 방법이 필요했다. 그래서 다익스트라는 동적으로 메모리를 할당하는 개념을 생각해냈다. 그는 ‘링크link‘라는 구조를 제안했는데, 오늘날 활성화 레코드activation record라고 부르는 것과 같다. 이것은 함수가 호출될 때마다 그 함수가 사용할 변수들을 위해 새롭게 할당되는 메모리 공간이다. 인자값, 리턴값, 복귀주소값은 물론이고 이 함수의 상태를 나타내 줄 각종 지역 변수와 레지스터 값 등이 이 메모리 공간 속에서 상대적인 위치로 자리 잡는다. 예를 들면, 복귀주소값은 ‘링크 구조’의 맨 처음 번지, 인자값은 그다음 번지, 리턴값은 그다음 번지와 같은 식으로 약속한다. 그러면 앞의 예에서 factorial(3)을 호출할 때, 고정된 메모리 번지에 인자값과 리턴주소값을 기록하는 것이 아니라, 메모리상에 새로 공간을 할당하고 그 첫 위치에는 리턴주소를 기록하고, 그 다음 위치에 인자값을 기록한 후 factorial 함수로 넘어간다. 그러면 factorial 함수는 ‘링크 구조’의 두 번째 위치에서 인자값을 읽어서 사용한다. factorial(3)을 처리하는 중에 factorial(2)를 호출하게 되면, 메모리에 존재하는 기존의 ‘링크 구조’에 새로운 ‘링크 구조’가 추가로 생성되어 붙게 된다. 따라서 기존의 인자값이나 복귀주소값을 덮어쓸 염려가 없어진다.
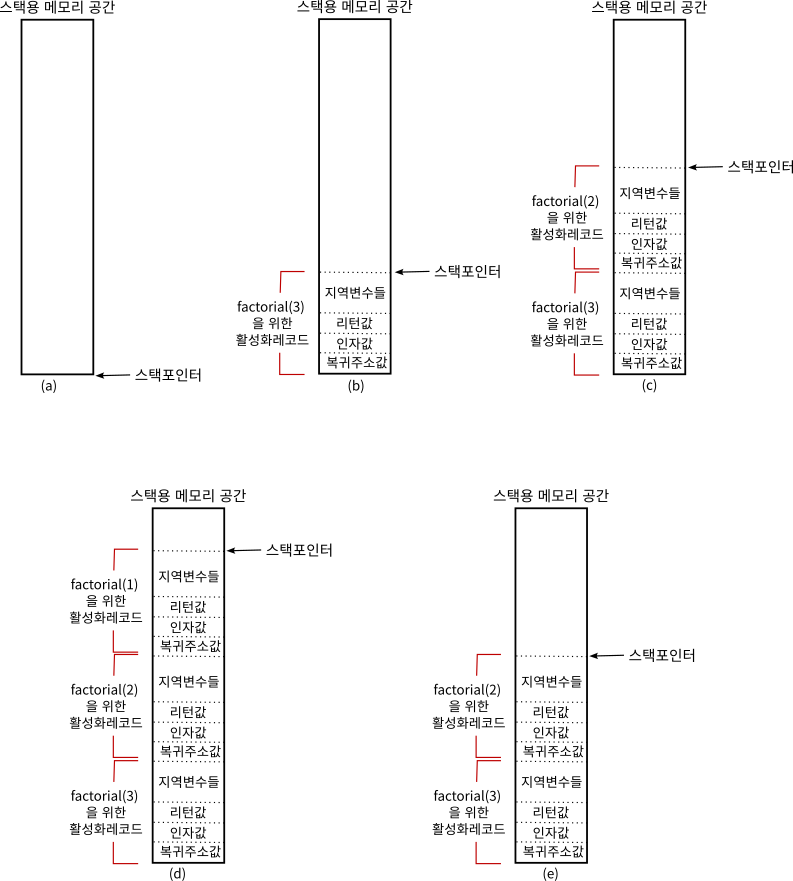
위의 그림에서 (a)는 아직 함수 호출이 없는 상태이다. factorial(3)이 호출되면 (b)처럼 활성화 레코드가 스택에 생성된다. factorial(3) 안에서 factorial(2)가 호출되므로 (c)처럼 새로운 활성화 레코드가 생성되었다. factorial(2) 안에서 factorial(1)이 호출되면 (d)처럼 활성화 레코드가 추가된다. 이제 factorial(1)이 작업을 마치게 되면 이것을 위해 생성된 활성화 레코드는 (e)와 같이 사라진다. 활성화 레코드 안에 있는 복귀주소값을 사용해서 factorial(2) 수행으로 돌아가게 되며 factorial(1)의 리턴값은 스택포인터를 기준으로 해서 알아낼 수 있다.
다익스트라는 ‘링크 구조’용 메모리 공간이 미리 할당되어 있는 식으로 생각했다. 함수가 호출되면 그 공간 안에서 ‘링크 구조’가 생기고 함수가 종료되면 ‘링크 구조’가 제거된다. ‘링크 구조’는 비어 있는 부분에 차곡차곡 생기기 때문에, 재귀적 호출이 이루어지면 ‘링크 구조’가 계속 늘어나다가 호출에서 되돌아오면 역순으로 사라지는 모양을 보여준다. 이것이 마치 물건을 차곡차곡 쌓았다가 다시 위에서부터 차례대로 치우는 모양 같다고 하여 ‘스택’이라는 이름을 가지게 되었다.5
구조적 프로그래밍
1950년대만 하더라도 프로그래밍은 아주 극소수의 전문가들이 하는 작업이었다. 기계어로 프로그램을 작성하는 일은 아주 고단한 일이었고 컴퓨터 하드웨어의 많은 제약으로 인해서 단순하게 끝낼 일도 복잡해졌다. 그래서 많은 사람들은 컴퓨터 하드웨어가 발전하면 프로그래밍 작업은 점점 줄어들 것이라고 생각했다.1
하지만 1960년대에 접어들면서 컴퓨터가 기업에 보급되기 시작했고 IBM 360과 같이 호환성을 가지는 컴퓨터가 등장하면서 오히려 프로그래머에 대한 수요는 폭발적으로 늘어났다. 컴퓨터 하드웨어는 늘어나지만 프로그래밍 기술은 발전하지 못하자 ‘소프트웨어 위기’라는 말이 나오기 시작했다. 프로그래머의 생산성을 높이기 위해서 고급 언어를 개발하려는 노력이 이어졌으나, 프로그래밍은 개개인의 재능에 의존했다.
다익스트라는 프로그래밍의 생산성을 높이고, 소프트웨어의 품질을 높이기 위해서는 GO TO 문을 사용하지 않아야 한다고 주장했다. 프로그램의 흐름을 이해하기 어렵게 만들기 때문이었다. 그는 이런 생각을 발전시켜서 ‘구조적 프로그래밍structured programming‘을 해야 한다고 주장했다.13
구조적 프로그래밍을 프로그래밍 기법의 측면에서 설명한다면 상당히 단순하다. 블록 구조block structure, 조건문if-then-else, 반복문while/for, 함수/서브루틴으로만 프로그램을 작성하면 된다. 당연히 GO TO 문은 포함되지 않는다. 어찌 보면 너무도 당연해 보이는 이야기이다. 그 이유는 현대의 프로그래밍 언어가 대부분 이를 따르고 있기 때문이다. 구조적 프로그래밍을 명시적으로 목표로 삼지는 않았지만 알골 언어가 이를 만족하고 있으며 파스칼Pascal, PL/I 등이 이를 계승했다.
다익스트라가 구조적 프로그래밍을 주장한 이유는, 프로그램의 정확성을 검증하기 쉽기 때문이었다. 그는 규모가 큰 프로그램의 정확성을 검증하기란 쉽지 않다면서, 전통적인 샘플링 방식의 테스트 방법은 오류가 있음을 증명할 뿐, 오류가 없음을 증명하지는 못한다고 일갈했다. 그는 프로그램의 정확성을 증명하는 것은 이미 가능하다는 전제를 깔고 다음과 같이 주장했다.
따라서 나는 “주어진 프로그램의 정확성을 증명할 방법이 무엇인가?”라는 질문에는 관심을 기울일 생각이 없고, 대신에 “프로그램의 크기가 크더라도 정확성을 증명하는 데 과도한 노력이 필요하지 않은 프로그램 구조가 무엇인가?”라는 질문에 집중해왔다. 결국은 “주어진 작업에 대해서 우리가 어떻게 아주 잘 구조화된 프로그램을 작성할 것인가?”라는 문제이다…
계산 작업을 정적인 프로그램 언어로 어떻게 만들 수 있을지에 대해 연구해 온 나는 그 여러 가지 가능한 구현 방식들 사이에서 단계적으로 추상화를 이루어 나가려면 엄격한 순서 규칙을 따라야 한다는 결론에 이르렀다. 특히, 순차식 컴퓨터를 위한 프로그램이 프로그래밍 언어의 기본 기호들을 나열하는 형태로 표현되는 경우에는, 그 순서 규칙은 대체alternative, 조건conditional, 반복repetitive문 및 프로시져 호출에 의해서 제어되어야 하며, 레이블label이 달린 지점으로 이동하는 점프문에 의해 제어되어서는 안 된다.10

답글 남기기