튜링상 관련 업적
대규모 인공지능 시스템의 설계와 제작을 선도했고, 인공지능 기술의 실용적 중요성과 상용화했을 때의 잠재적 영향력을 시연해 보였다.
1994년 튜링상 선정 이유
EPAM
EPAM은 Elementary Perceiver and Memorizer의 약자이다. 한국어로 번역하자면 ‘기초적인 지각 및 기억 프로그램’ 정도가 될 듯싶다. 사실 이 이름만으로는 무슨 일을 하는 프로그램인지 알아채기가 쉽지 않다. 좀 더 구체적으로 표현한다면 ‘단어를 알아채고 기억하는 프로그램’이라고 부를 수 있다.
EPAM의 시작은 허버트 사이먼 교수가 에드 파이겐바움에게 연구 주제를 주면서 시작되었다.
“인간은 글을 어떻게 이해하는 걸까?”
글을 이해하려면 글에 사용된 단어들을 이해해야 하는데, ‘이해’를 위해서는 단어를 ‘학습’해야만 한다. 단어를 ‘학습’한다는 것은, 그 단어의 의미 혹은 맥락을 ‘기억’하는 것이라고 볼 수 있다. 사람이 어떤 단어를 마주치면 시각적으로 그 형태를 지각하게 되고, 그 형태에 사상mapping되어 있는 의미를 기억 속에서 끄집어낸다. 그래서 단어를 지각하고 기억하는 기능이 반드시 필요하다.
언어 학습verbal learning은 이미 교육학자나 심리학자들이 관심을 가져온 영역이었고 관련 연구가 활발히 진행되어 오고 있었다. 그래서 파이겐바움은 기존의 연구를 차용했다. ‘무의미한 세 글자 단어nonsense trigram‘를 사용한 연구였다. 알파벳 세 개로 구성된 단어를 사용해서 인간의 언어 학습을 연구하는 분야였는데, 이 단어는 실제로는 사용되지 않는 무의미한 단어이고 첫 글자와 마지막 글자는 자음, 가운데 글자는 모음으로 구성되었다. 예를 들면 DAX, JIR 같은 것이다. 무의미한 단어를 사용하는 이유는, 학습 이론을 실험하기 위해서 사람을 사용해야 하는데 이미 아는 단어를 사용하면 학습을 실험할 수 없기 때문이었다.
EPAM은 두 가지 실험에 초점을 맞추었다. 먼저 연관 단어 실험이다. 두 개의 단어가 연관되어 있다고 보여준 후에 나중에 그중 한 단어를 보여주면 다른 단어를 기억하게 하는 실험이다. 또 다른 실험은 목록 실험이다. 단어의 목록을 보여주고 후에 그 목록을 기억하게 하는 실험이다. 여기서는 전자의 실험에 대해서만 구체적으로 설명하겠다.
파이겐바움은 인간의 뇌가 연관 정보를 저장할 것으로 추정했다. 이 연관 정보를 Cue라고 불렀다. 그래서 연관된 두 개의 단어가 주어지면 인간의 뇌는 첫 번째 단어를 보았을 때 두 번째 단어를 연상시킬 수 있는 Cue를 어딘가에 저장한다. 따라서 다음과 같은 자료구조가 필요하게 된다.
1. (첫 번째 단어의 형태적 최소 정보) -> Cue
2. Cue -> (두 번째 단어)1에서 주의할 점은 (첫 번째 단어)가 아니라 (첫 번째 단어의 형태적 최소 정보)라는 점이다. 우리는 DAX라는 단어를 보았을 때 첫 글자가 D이고 두 번째 글자가 A이고 세 번째 글자가 X임을 바로 연상시킨다. 그것은 이미 그 정보가 학습되었기 때문이다. 만약 한 번도 배운 적이 없는 히브리어나 아랍어 단어가 주어지면 우리는 그것을 그림으로 받아들인다. D라는 알파벳을 처음 배울 때 우리는 그것이 수직선에 볼록한 선이 붙어 있는 모양과 연결 지어 기억했다. 파이겐바움은 인간이 단어를 인식할 때도 결국은 그런 형태적 정보를 사용한다고 보았고 그래서 EPAM에서도 그런 정보를 사용하도록 했다.
또한 파이겐바움은 인간의 뇌가 게을러서(?) 최소의 정보만을 저장하려 한다고 보았다. 그래서 DAX라는 단어의 모든 형태적 정보를 저장하는 것이 아니라, 기존에 학습했던 단어들과 구별하는 데 필요한 최소한의 정보만 저장하는 식으로 구현했다. 이는 Cue 정보에서도 마찬가지이다. Cue 정보는 연관된 단어를 찾기 위해 필요한 정보인데 이것도 필요한 최소 정보만 저장하는 식이다.
위의 1, 2 동작을 구현하기 위한 방법은 여러 가지가 있을 수 있는데, 파이겐바움은 혁신적으로 이진트리binary tree 방식을 사용했다. 그는 이것을 차별 망discrimination net이라고 불렀는데 오늘날 결정 트리decision tree라고 부르는 방식의 시초이다.
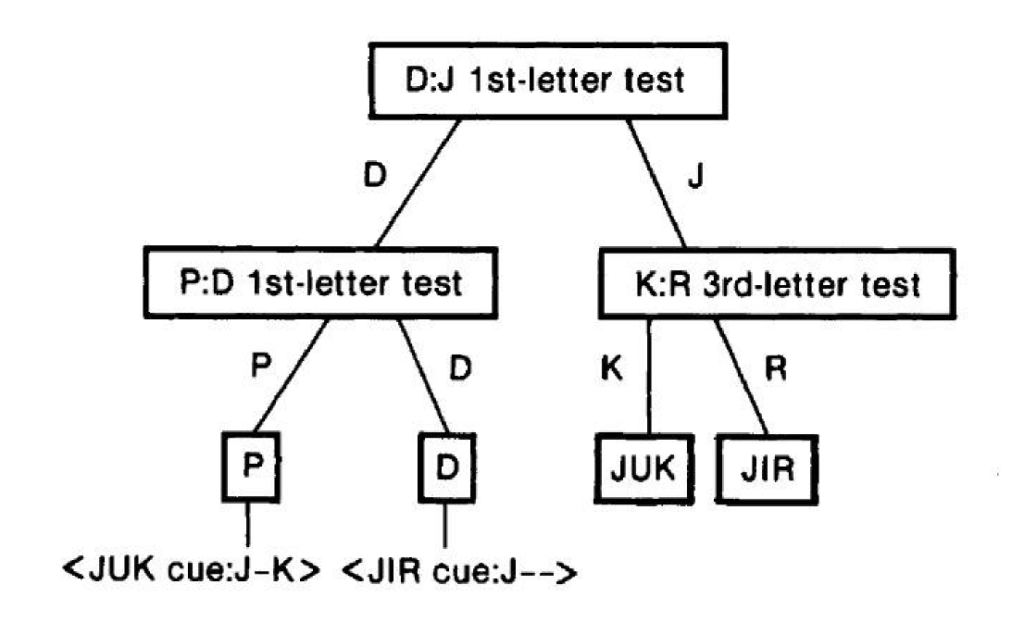
위의 그림은 EPAM에서 DAX-JIR, PIB-JUK 라는 두 개의 단어 쌍을 학습시켰을 때 내부에 구성되는 차별 망의 형태이다. 편의상 단순화시켰음에 유의하자. 차별 망은 학습 과정에서 생성되고 갱신되며, 기억 과정에서 검색된다. 기억 과정에서 나타나는 두 단계, 즉 앞의 예에서 들었던 1, 2 과정은 각각 트리의 왼편과 오른편에서 진행된다.
EPAM은 인공지능의 역사에서 그 의미가 남다르다. 지금 보면 뻔한(?) 내용으로 보일 수도 있겠지만, 이 시스템이 개발된 시기가 1950년대 후반임을 명심하자. 아직 대부분의 컴퓨터 프로그램이 기계어로 작성되고 있었고 포트란 언어가 발표된 지 아직 몇 년 지나지 않은 상황이었다. 리스프 언어는 아직 세상에 모습을 드러내지도 않았다.
인공지능 분야에서 그나마 눈에 띄는 결과물은 로직 시어리스트Logic Theorist 밖에 없었다. 파이겐바움의 지도교수인 허버트 사이먼이 만든 로직 시어리스트는 수학적 추론 규칙을 사용해서 자동으로 새로운 정리를 찾아내는 프로그램이었다. 이것은 뇌의 추론 능력을 인공으로 만들어내었다는 점에서 획기적이었지만, 뇌의 학습 능력은 빠져 있었다. 자동으로 학습하는 프로그램은 EPAM이 최초라고 해도 무방하다.
EPAM을 개발하기 위해서 파이겐바움은 IPL-V라는 프로그래밍 언어 개발에도 참여했다. IPL-V는 로직 시어리스트 개발에 사용했던 IPL 언어의 개선된 버전이었고, 리스트 구조를 다룰 수 있는 언어였다.
전문가 시스템
논리학에는 삼단논법이라는 것이 있다.
A -> B 이고 B -> C 이면 A -> C 이다.사용 사례를 들자면, ‘나는 사람이다’ 그리고 ‘사람은 죽는다’. 고로 ‘나는 죽는다’와 같은 논리 흐름이 있을 수 있겠다.
삼단논법은 수학뿐만 아니라 물리학, 화학, 사회과학에도 사용될 수 있다. 그것은 분야를 따지지 않는 명제이다.
초기의 인공지능 연구는 이러한 수학적 추론에 집중했다. 컴퓨터의 기반이 논리학이었으므로 놀랄 일은 아니다. 하지만 이 방법론은 큰 벽에 부딪혔다. 당시에 인공지능을 적용하던 대표적인 사례가 로봇팔이었다. 어떤 공간에 물체들을 놓고 카메라로 물체를 인식한 후에 로봇팔로 이동하는 작업을 구현하려 했다. 이 시스템에 인간은 다음과 같은 명령을 내릴 수 있다.
“빨간색 블록 위에 놓여 있는 세모 블록을 오른쪽 끝에 있는 파란색 블록 위로 옮겨라.”
단순해 보이는 이 작업이 수학적 추론 인공지능 방식에서는 구현하기 쉽지 않았다. 공간에 있는 물체들의 상태를 모두 수식으로 표현한 후에, 그렇게 만들어진 수식들에 수학적 추론을 적용하여 원하는 최종 상태의 수식을 도출해 내야 했는데 공간이 복잡해지면 답을 구하기가 점점 어려워졌다.
파이겐바움은 조금 다른 방법론으로 접근했다. 모든 분야에 다 맞는 방법을 찾을 필요는 없다는 것이었다. 화학이면 화학, 의학이면 의학. 각 분야에는 그 분야에서 쌓인 전문적인 정보들이 있다. 그 정보들을 모아서 정리하면 그 분야의 문제 해결에 사용할 수 있으리라고 본 것이다. 여기서 말하는 전문 분야는 ‘도메인domain‘이라고 표현했고, 도메인에서 사용하는 전문 정보는 지식knowledge이라고 표현했다. 도메인의 지식을 사용하여 규칙을 만들어내는 시스템은 ‘전문가 시스템expert system‘이라고 불렸다.
최초의 전문가 시스템은 파이겐바움이 조슈아 레더버그, 칼 제라시Carl Djerassi와 함께 개발한 DENDRAL이다.* DENDRAL은 Dendritic Algorithm의 약자이다. 원래의 목적은, 질량분석기mass spectrometer 를 통해 얻은 정보를 통해서 물질의 화학 구조를 추정해 내는 데 있었다. 시작은 조슈아 레더버그였다. 그는 외계에서 온 운석의 정체를 알아내고 싶었고, 화학자 칼 제라시의 방법론을 파이겐바움을 통해 컴퓨터로 구현해 보려 했다.
사실상 DENDRAL은 가능한 모든 경우의 수를 시도하는 알고리듬이다. 즉 어떤 질량 값이 주어졌을 때 그 질량 값을 만들 수 있는 분자들의 모든 조합을 따져보면 된다. 만약 질량 값이 작다면 경우의 수가 작겠지만 질량 값이 커지면 기하급수적으로 증가한다. 그래서 현실적으로 발생하지 않을 경우는 제외할 필요가 있는데, 이때 도메인 지식domain knowledge이 개입한다. 이미 화학자들은 어떤 식의 분자 조합이 불가능함을 알고 있으므로 그런 경우는 제외하는 것이다. 이렇게 해서 만든 최종 시스템은 휴리스틱 Dendral이라고 불렸다. 휴리스틱 Dendral은 리스프 언어로 개발되었다.
휴리스틱 Dendral이 완성되자 파이겐바움 팀은 조금 더 욕심을 냈다. 그들은 새로운 도메인 지식을 생성해 내는 시스템을 만들고 싶었다. 화학적 결합 정보와 그 결과물의 질량분석 값들을 입력으로 받아서 이를 학습한 후에 그럴듯한plausible 새로운 규칙 혹은 관계를 만들어내는 것이었다. 이렇게 생성된 새로운 규칙은 휴리스틱 Dendral에 추가해서 적합 여부를 판별했다. 새로운 규칙을 만들어내는 시스템은 메타 Dendral이라고 불렸다.
칠판 모형
칠판 모형blackboard model은 카네기 멜런 대학교의 Hearsay 시스템에서 처음 등장한 것으로 여겨진다.6 아직 다듬어지지 않은 상태였던 이 모형은, 파이겐바움이 잠수함 탐지 시스템인 HASP 시스템에 성공적으로 활용하면서 유용함이 검증되었고 이후 많은 인공지능 시스템에 채택되었다.†
‘칠판’이라는 단어가 이 모형의 큰 특징을 드러내고 있다. 교실에서 칠판은 여러 사람이 공유하는 자원이다. 선생님들이 공유할 수도 있고, 선생님과 학생이 공유할 수도 있다. 또한, 칠판에 적힌 것들은 영구불변이 아니라 언제든지 지우개로 지울 수 있고 수정될 수 있다. ‘칠판 모형’이란, 여러 주체에 공유되면서 내용이 수정될 수 있는 모형이다. 누군가는 이것을 두고 ‘별로 특별할 것도 없는 것’이라고 평가절하할 수도 있겠으나 이때가 1970년대 초반이었음을 상기하자.
레디 교수가 스탠퍼드에서 아날로드-디지털 변환기로 처음 음성 인식 연구를 시작했을 당시에는 아직 인공지능에 대한 모형이 제대로 잡혀 있지 않은 상황이었다. ‘수학적 추론’에 기반한 인공지능과 ‘신경망’에 기반한 인공지능이 그나마 연구되던 상황에서 ‘전문가의 지식’을 기반으로 하는 인공지능 연구는 파이겐바움과 레디가 이제 첫발을 내딛고 있었다. ‘전문가의 지식’을 어떻게 컴퓨터에서 사용할지에 대해 명확한 모형은 제시되지 않은 상황이었다.
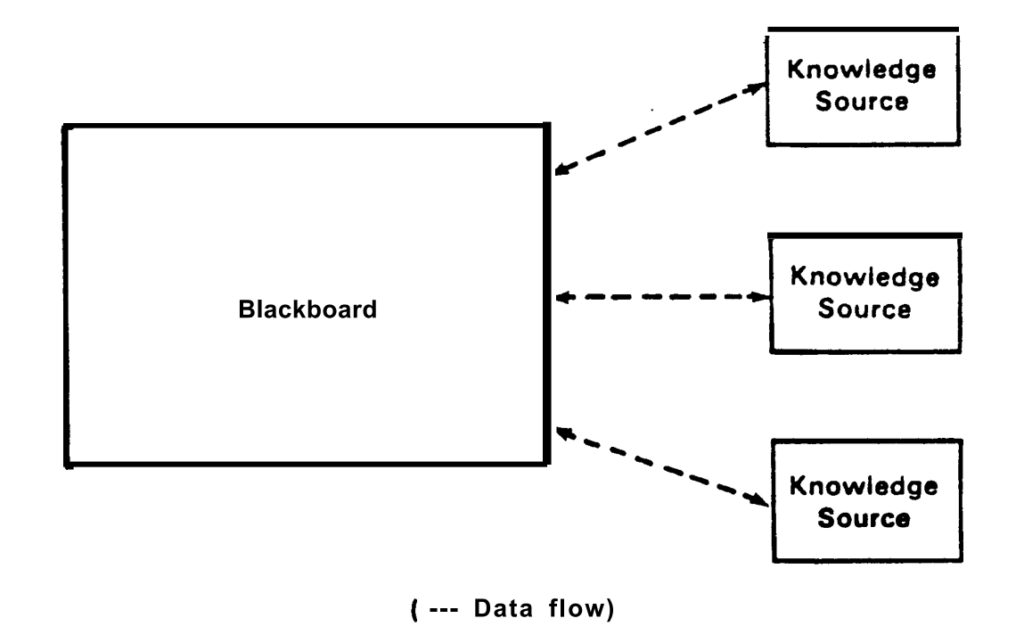
칠판 모형의 개념은 위의 그림으로 표현될 수 있다.6 좀 허무할 정도로 단순하다. 칠판이라는 공용의 데이터베이스가 있고 이 안에는 인공지능 알고리듬에 사용되는 여러 규칙들이 저장되어 있다. 이 규칙들은 상당 부분 전문가 지식knowledge을 통해 만들어진다. 문제는 이 지식이 항상 정확하다거나 완전하다고 할 수 없다는 점이다. 언제나 새로운 지식이 옛 지식을 대체할 수 있는 법이기 때문이다.
그래서 외부로부터 지식 정보가 주입되는 경로들이 존재한다. 이것이 한 개만 있으라는 법은 없다. 이렇듯 새로운 지식을 제공하는 주체를 지식 원천Knowledge source이라고 부른다. 칠판에 저장된 정보(규칙)들은 지식 원천에 의해서 생성되고 수정되고 삭제될 수 있다.
음성 인식을 하는 소프트웨어를 개발한다고 해보자. 아날로그 음성 신호를 디지털 정보로 바꾼 후에 그 신호가 어떤 단어인지를 알아내야 한다. 이게 수학적 추론에 의해 결정될 수 있다면 굳이 전문가 지식을 사용할 필요가 없다. 그냥 수식을 적용하면 되기 때문이다. 그런데 현실은 그렇지 못하다. 예를 들어 ‘사과’라는 단어를 음성 인식한다고 해보자. ‘사과’라는 음성 신호(음파)를 마이크mic로 포집해서 디지털 데이터로 변환했을 때 그 값은 항상 일정하지 않다. 누가 발음하느냐에 따라 다르고, 목 상태에 따라 다르고, 발음 속도에 따라 다르고, 그날 대기압에 따라 다를 수 있다. ‘사가’라는 단어의 디지털 데이터와 혼동될 가능성도 있다. 그래서 음성 인식 소프트웨어는 입력된 음성 디지털 데이터에 대해 일종의 ‘가설hypothesis‘을 적용하게 된다. 예를 들어, 데이터 값이 2% 정도 차이 나는 것은 무시할 수 있다고 정할 수 있다.
이런 가설들이 위의 그림에서 ‘칠판blackboard‘에 저장된다. 하지만 이 가설은 말 그대로 가설일 뿐이다. 음성학 연구가 진행되어서 새로운 가설이 나올 수도 있고, 전자공학이 발전하여 더 정교한 아날로그-디지털 변환기가 나올 수도 있다. 이럴 때마다 칠판에 저장된 정보(가설 혹은 규칙)들은 바뀌거나 새로운 것으로 대체될 수 있다. 여기서 음성학과 전자공학은 각각 하나의 지식 원천Knowledge source이 된다. 그리고 지식 원천은 서로 독립적으로 개입한다.
처음부터 칠판 모형이라는 이름을 붙이고 시스템을 개발했을 것 같지는 않다. 효과적인 인공지능 시스템을 개발하다 보니 위와 같은 모형이 도출되었고 거기에 이름을 붙이다 보니 ‘칠판 모형’이 되었다고 하면 지나친 비약일까?‡
음성인식
라지 레디가 박사 주제로 음성인식을 시작한 때가 1963년이므로 50년이 넘는 세월이 지났다. 50년 동안 인공지능 기술이 겪었던 어려움을 생각하면 변변한 컴퓨터도 없이 그 분야에 뛰어든 용기가 대단하다고 느껴진다. 오늘날 애플의 ‘시리’, 마이크로소프트의 ‘코타나’ 등과 같은 음성인식 시스템은 레디 교수의 연구를 뿌리로 하고 있다.
레디 교수는 카네기 멜런 대학교에서 여러 음성인식 시스템들을 개발했다. 박사 학위 주제이기는 했지만 그가 한 우물을 계속 팔 수 있었던 배경에는 정부의 재정적 지원이 있었다. 1971년에 ARPA는 음성인식에 관한 연구를 지원하기로 결정하면서 카네기 멜런 대학교의 앨런 뉴얼 교수를 연구그룹의 위원장으로 임명했다.7 앨런 뉴얼 교수가 이끄는 연구그룹은 음성인식에 필요한 다양한 인공지능 기술을 정리한 보고서를 제출했고 이를 기반으로 ARPA는 많은 연구 과제를 추진했다. ARPA는 음성인식 기술의 완성도를 평가하기 위한 척도를 제시했고, 여러 경쟁 시스템들 중에서 레디 교수가 개발한 시스템이 항상 돋보이는 결과를 보여줬다.
레디 교수가 개발한 시스템으로는 Hearsay-I, Hearsay-II, Dragon, Harpy, Sphinx-I, Sphinx-II 등을 들 수 있다.
Hearsay-I은 연속 음성 인식continuous speech recognition이 구현된 최초의 시스템이다. 즉, 단어 단위뿐만 아니라 문장 단위로 인식을 할 수 있었다.7 Hearsay-II는 ‘칠판 모형’이 적용된 최초의 시스템이다.6 Dragon에서는 ‘은닉 마르코프 모형Hidden markov model’이 최초로 사용되었다.8 Harpy는 빔 검색Beam search이라는 방식을 처음 소개했다. 빔 검색은 그래프에서 어떤 노드를 찾을 때 사용하는 기법 중 하나로 메모리 크기에 제한이 있을 때 매우 유용해서 현재도 많이 사용되고 있다.7 Sphinx-I은 화자 독립 음성 인식을 최초로 시연한 시스템이다.7 화자 독립speaker-independent이란, 사람에 따라 달라지지 않는다는 의미이다. ‘사과’를 발음하는 사람이 홍길동이건 전우치건 상관하지 않는다. Sphinx-I 이전까지는 화자 종속적이었다. 홍길동의 발음으로 학습시킨 음성인식 시스템은 전우치의 발음을 인식하지 못했다.

답글 남기기