튜링상 관련 업적
알고리듬과 자료구조의 설계 및 분석에 있어서 근본적인 성취를 거두었다.
1986년 튜링상 선정 이유
점근적 복잡도
사전적으로 번역하면 의미가 애매해지는 단어들이 있다. ‘점근적 복잡도’가 그러하다. 원래 영어로는 asymptotic complexity이다. 단언할 수는 없으나 영어로 먼저 등장했고 후에 한국의 누군가가 이것을 ‘점근적 복잡도’라고 번역했으리라 짐작한다. 그런데 ‘asymptotic’과 ‘점근’이라는 단어를 사전에서 찾아보면 다음과 같다.
asymptotic: (of a function, series, formula, etc) approaching a given value or condition, as a variable or an expression containing a variable approaches a limit, usually infinity8
점근: 점점 가까워짐.9
두 단어의 의미를 비교해보면 ‘점근’이라고 번역하는 것이 맞는지 의문이 든다. Asymptotic의 의미에서 중요한 부분은 변수가 무한대로 커진다는 상황 조건이다. ‘점근’이라는 단어에는 그런 뉘앙스가 전혀 담겨 있지 않다. 하지만 이미 이런 번역이 굳어져 버렸으니 점근적 복잡도라는 단어를 보면 변수가 무한대로 커지는 경우를 머릿속에 그릴 수 있어야겠다.
왜 그래야만 하는지 논리적인 이유가 확실하게 있지는 않지만, 우리는 어제보다 오늘이, 오늘보다 내일이 더 나아지기를 바라며 노력한다. 그렇게 살도록 학습(?)되었다. 그렇다면 오늘이 어제보다 더 나은지 아닌지를 알 수 있어야만 할 것이다. 그래서 우리는 뭔가를 비교하는 방법도 꾸준히 만들어왔다. 정량적인 비교를 위해서 많은 지수들이 만들어졌다. 국내총생산(GDP), 체지방 비율, 문맹률 등등이 있다.
알고리듬도 마찬가지이다. 그 배경은 여러 가지이다. 박사 학위를 받기 위해서, 자아실현을 위해서, 경쟁업체를 이기기 위해서, 회사에서 짤리지 않으려고 등등, 각자의 동기는 다르겠지만 아무튼 어떤 문제를 해결하는 데 걸리는 시간과 공간을 줄이기 위해서 많은 컴퓨터 과학자/공학자들이 노력한다. 그리고 그렇게 해서 만든 알고리듬이 다른 경쟁 알고리듬보다 얼마나 더 좋은지를 입증해야 한다.
가장 확실한 방법은 직접 프로그램을 작성해서 보여주는 것이다. 내 알고리듬에 따라 작성된 프로그램이 다른 알고리듬으로 만든 프로그램보다 더 빨리 일을 끝낸다면 아주 깔끔하게 승부를 끝낼 수 있다. 그런데 이게 그렇게 단순치가 않다.
첫 번째로, 완벽하게 동일한 환경에서 프로그램들을 비교하기가 과거에는 현실적으로 어려웠다. 동일한 컴퓨터 시스템에서 프로그램이 실행되어야 공정하다고 볼 수 있을 텐데 컴퓨터 자체가 귀하다보니 각 대학이나 연구소마다 사용 가능한 컴퓨터가 제각각이었다. 또한, 컴파일러도 컴퓨터 제조업체별로 각자 만들었기 때문에 컴파일러의 성능도 들쑥날쑥이었다. 그러니 누군가 나타나서, “하니웰 컴퓨터로 내 알고리듬을 실행해보니 기존의 알고리듬보다 수행시간이 100초 줄어들었다”라고 주장하더라도 그것이 알고리듬이 좋아서 그런건지 하니웰 컴퓨터가 좋아서 그런건지 애매한 경우가 있었다.
두 번째는 입력 데이터의 양에 따라 결과가 뒤집어질 수도 있다. 전문적으로 요리를 하는 분들이 하는 말 중에, 5인분 만들기와 100인분 만들기는 완전히 차원이 다르다는 이야기가 있다. 그래서 5인분을 잘 만든다고 해서 100인분도 잘 만든다고 단언하기는 어렵다. 알고리듬도 마찬가지이다. 입력값이 100개일 때는 더 빨리 끝나던 프로그램이 입력값이 10,000개일 때는 오히려 더 늦게 끝날 수도 있다.
그래서 호프크로프트는 점근적 복잡성이라는 개념을 적극 지지했다. 점근적 복잡성에서는 알고리듬의 상수 요소constant factor를 무시하고 입력의 크기가 아주 커질 때의 성능에 초점을 둔다. 위에서 첫 번째 쟁점은, 알고리듬을 구현한 프로그램의 실행 시간이 컴퓨터의 성능에 영향을 받는다는 것이었다. 이것은 알고리듬의 상수 요소와 관련된다. 다음과 같은 알고리듬이 있다고 하자.
n := 100;
for ( i=0; i<n; i++) {
sum = sum + i;
}0에서부터 99까지 더하는 일을 하는 알고리듬이다. 이 알고리듬을 실제로 프로그램으로 작성하여 수행한다고 하면 실행시간은
100 * 덧셈 시간이라고 볼 수 있다. 100은 이 알고리듬에서 입력의 크기에 해당한다. 그렇다면 덧셈 시간은 무엇이 결정할까? 그것은 컴퓨터 구조가 결정한다. 마이크로프로세서의 구조, 메모리 접근 속도 등에 좌우된다. 만약 위의 알고리듬에서 n의 값을 10,000으로 바꾸더라도 이 덧셈 시간에는 변함이 없다. 그래서 이것은 알고리듬에서 상수 요소에 해당한다. 점근적 복잡성에서는 이 상수 요소를 무시한다. 따라서 위의 알고리듬의 성능을 따질 때는 n이라는 변수만 생각한다.
위에서 언급한 쟁점 중 두 번째는 입력의 크기였다. 입력의 크기가 작을 때와 입력의 크기가 클 때 알고리듬 사이의 우위가 달라질 수 있다는 것이었다. 점근적 복잡성에서는 입력 크기가 작은 경우는 무시한다. 알고리듬의 좋고 나쁨은 입력의 크기가 아주 클 때 나타난다고 보는 것이다. 입력의 크기가 커지면 알고리듬의 성능이 특정 항목에 의해 좌우되는 경향이 나타난다. 예를 들어 두 개의 알고리듬이 있고 그 실행시간이 다음과 같이 표현된다고 가정해보자.


위에서  은 입력 데이터의 크기이다. (이것은 값 자체의 크기일 수도 있고 아니면 데이터의 개수일 수도 있다.) 의 변화에 따른 실행시간의 값을 그래프로 그리면 다음과 같다.
은 입력 데이터의 크기이다. (이것은 값 자체의 크기일 수도 있고 아니면 데이터의 개수일 수도 있다.) 의 변화에 따른 실행시간의 값을 그래프로 그리면 다음과 같다.
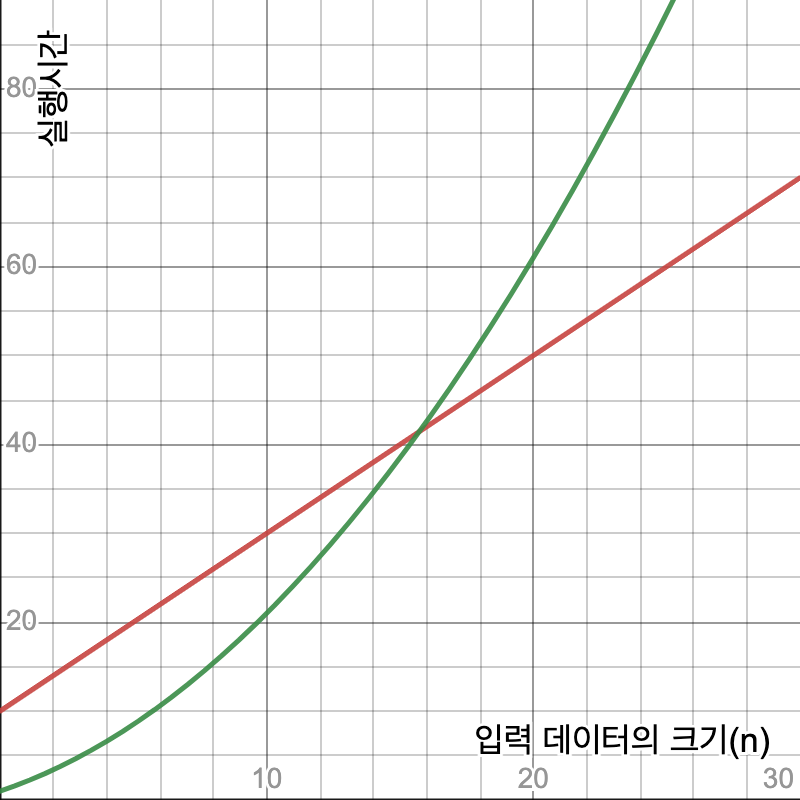
의 값이 12 이하 일때는  가 더 빠르지만 의 값이 13 이상일 때는
가 더 빠르지만 의 값이 13 이상일 때는  이 더 빠르다. 그러면 어느 알고리듬이 더 좋다고 해야 할까? 점근적 복잡도 입장에서는 가 더 좋다. 이는 어찌보면 합리적이다. 입력 데이터의 크기가 작을 때는 사실 어느 알고리듬을 써도 별 문제가 없다. 모두 감내할 수 있는 시간 내에 일을 끝낼 수 있기 때문이다. 하지만 입력 데이터의 크기가 커질 수록 는 너무 오래 걸려서 현실적으로 사용이 불가능하다.
이 더 빠르다. 그러면 어느 알고리듬이 더 좋다고 해야 할까? 점근적 복잡도 입장에서는 가 더 좋다. 이는 어찌보면 합리적이다. 입력 데이터의 크기가 작을 때는 사실 어느 알고리듬을 써도 별 문제가 없다. 모두 감내할 수 있는 시간 내에 일을 끝낼 수 있기 때문이다. 하지만 입력 데이터의 크기가 커질 수록 는 너무 오래 걸려서 현실적으로 사용이 불가능하다.
알고리듬의 성능을 점근적 복잡도로 평가하려는 호프크로프트의 시도가 쉽게 받아들여지지는 않았던 듯싶다.
점근적 복잡도는 논쟁을 불러일으켰습니다. 평면성에 대한 작업이 있기 전에 나는 점근적 복잡도에 관한 강연을 한 적이 있었습니다. 거기서 나는 “알고리듬을 위한 설계 기준으로서 최악의 경우에 대한 점근적 복잡도를 사용해야 하는 이유”를 말했습니다. 현장에서 일하는 사람들은 이 개념을 받아들이지 못했습니다.10
지금은 알고리듬을 평가할 때 점근적 복잡도가 당연하게 사용되고 있다. 이때 사용되는 표기법이 big O이다. 앞의 예에서 을 big O로 표현하면  이 되고 를 big O로 표현하면
이 되고 를 big O로 표현하면  가 된다. big O에서는 상수 요소가 무시되며 대세를 결정하는 항, 즉 가장 차수가 높은 항을 표기한다.
가 된다. big O에서는 상수 요소가 무시되며 대세를 결정하는 항, 즉 가장 차수가 높은 항을 표기한다.

답글 남기기