멀틱스
CTSS가 실질적인 성공을 거두었고, MAC 프로젝트라는 대형 프로젝트가 정부의 확실한 재정적 지원 속에 출범하게 되자, 자연스럽게 다음 버전이 추진되었다. CTSS는 시분할 시스템의 개념을 검증하기 위한 시험용 시스템이었으므로, 그다음 수순은 제대로 된 시분할 시스템이었다. 마치 CTSS 직전에 티거 교수가 그러했던 것처럼 새로운 시스템은 많은 기능을 추구하는 방향으로 흘렀다.
판매용으로 만들어지는 대형 컴퓨터에 어떤 것들이 들어가면 좋을지에 대해서 생각해 보았고 그것이 멀틱스의 시작이었습니다. 그런 시스템을 만드는 것이 비전이었습니다. 우리는 제조사들에게 참여를 권유하기 시작했습니다.2
멀틱스Multics는 Multiplexed Information Computing Service의 약자이다. 멀티플렉스multiplex란 하나의 통로에 여러 개의 메시지를 번갈아 가며 보내는 것을 말하는데, ‘시간-공유time-sharing‘보다 더 적절한 표현인 듯싶다.
멀틱스를 위한 하드웨어 시스템은 제너럴일렉트릭 사가 담당했다. IBM은 멀틱스 팀의 요청에 그리 적극적으로 나오지 않았기 때문에 제외되었다. 제너럴일렉트릭은 출시한 지 얼마 되지 않았던 GE 635 모델을 수정해 주겠다고 약속했다. 그들은 새로운 시장을 찾고 있었다. 그리고 벨연구소도 손을 내밀었다. 벨연구소는 보유하고 있던 IBM 7090 컴퓨터를 모두 교체할 새로운 컴퓨터를 찾고 있었다.
1964년 가을에 본격적으로 시작된 멀틱스 프로젝트는 1965년에 관련 논문을 대거 발표하면서 큰 주목을 끌었다. 시스템의 사양을 미리 공개하고 개발하는 경우가 드물던 때였다.
멀틱스의 주요 특징은 다음과 같다.
- 세그멘테이션segmentation과 페이징paging을 사용한 메모리 관리
- 계층형 파일 시스템
- 링 레이어 방식의 권한 관리
- 고급 언어 PL/I 을 사용한 개발
- 메모리 번지를 이용한 파일 데이터 접근
- 셸shell 환경
메모리 관리
멀틱스는 가상메모리virtual memory 환경을 제공했다.7 가상메모리란, 실제 존재하는 메모리보다 더 큰 용량의 메모리가 있는 것처럼 프로그램을 속이는 기법이다. 예를 들어 컴퓨터에 장착된 메모리가 1메가바이트라고 가정해 보자. 이 메모리의 시작 번지가 0이라고 한다면 끝 번지는 16진법으로 표기하면 FFF,FFF가 된다. 따라서 프로그래머는 프로그램을 작성할 때 사용되는 메모리 번지가 이 주소 범위 안에 들어오도록 주의해서 작성해야 한다. 그런데 막상 이 컴퓨터의 프로세서가 다룰 수 있는 메모리의 크기는 훨씬 클 수 있다. 만약 32비트 컴퓨터라고 한다면 최대 4기가바이트 크기의 메모리 주소를 지원한다. 만약 가상메모리 기법을 사용할 수 있다면 프로그래머는 마치 이 컴퓨터에 4기가바이트의 메모리가 장착되어 있는 것처럼 프로그램을 작성할 수 있다.
실제 장착된 메모리의 용량은 1메가바이트인데 프로그램은 4기가바이트의 주소 공간을 사용하는 것이 어떻게 가능할까? 약간의 트릭(이라 쓰고 속임수라고 읽는다)을 사용한다. 4기가바이트 중에서 1메가바이트 만큼 제외한 주소 공간은 사실상 디스크에 저장된다. 4기가바이트라는 주소공간을 1메가바이트 단위로 쪼갠 다음에, 프로세서가 당장 접근하는 1메가바이트 조각만 메모리에 올려 놓는 것이다. 만약 프로세서가 현재 메모리에 올라와 있지 않은 주소 공간을 접근하면 현재 올라와 있는 데이터는 모두 디스크로 저장하고, 새로 접근하는 번지가 포함된 1메가바이트 조각을 디스크에서 읽어서 메모리로 가져온다. 이런 식의 가상메모리 구현 방법을 페이징paging 이라고 부른다.
이런 트릭을 사용하려면 프로세서가 접근하는 메모리 번지가 현재 메모리에 올라와 있는 주소공간에 해당하는지를 알아낼 방법이 필요하다. 이는 하드웨어적으로 처리되어야 하는 사항이다. 이런 수정 사항을 IBM은 받아들이려 하지 않았고 제너럴일렉트릭은 적극적으로 대응했기 때문에 MIT는 제너럴일렉트릭과 손을 잡았다.
세그멘테이션segmentation은 프로그램이 사용하는 메모리 공간을 기능 혹은 역할에 따라 나누는 것을 말한다. 예를 들어 인구조사 정보에서 통계를 뽑아내는 프로그램이 있다고 가정해 보자. 이 프로그램이 사용하는 메모리 공간은, 코드를 위한 메모리 공간과 통계 데이터를 위한 메모리 공간으로 나뉜다. 그리고 만약 코드가 공용 라이브러리의 함수를 사용한다면 공용 라이브러리의 함수는 이미 메모리에 상주하고 있을 수도 있으므로 별개의 메모리 공간으로 간주하는 것이 좋을 수 있다. 따라서 이 프로그램을 위한 메모리는 통계 프로그램 코드를 위한 메모리 공간, 공용 라이브러리 함수를 위한 메모리 공간, 통계 데이터를 위한 메모리 공간으로 구분될 수 있고 각각 다른 접근 권한으로 관리되는 것이 필요할 수 있다. 이렇게 다르게 관리되는 메모리 공간을 세그멘트segment라고 부르고 세그멘트를 사용하는 것을 세그멘테이션이라고 부른다.
각 세그멘트는 세그멘트 디스크립터segment descriptor라는 하드웨어 구조를 통해 관리된다. 세그멘트 디스크립터는 해당 세그멘트가 사용하는 가상 주소 공간에 대한 정보와 해당 세그먼트가 허용하는 접근 권한 등에 대한 정보를 담고 있다.
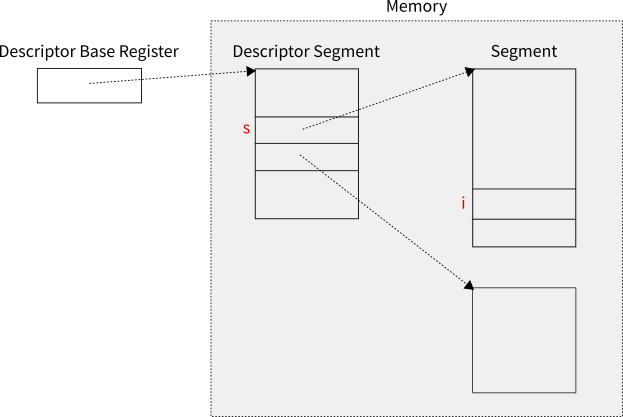
위의 그림은 멀틱스가 처음 구현된 GE 645 컴퓨터에 사용된 세그멘테이션의 전체적인 구조를 개념적으로 그려본 것이다. 세그멘테이션에서는 메모리에 있는 특정 값을 접근하려면 항상 두 개의 숫자가 필요하다. 하나는 세그먼트 번호이고, 다른 하나는 세그먼트 안에서의 위치값이다. 위의 그림에서 s와 i가 각각 여기에 해당한다.
프로그램에서 메모리의 주소는 항상 s와 i의 쌍으로 이루어지지만 프로그래머는 i만 인지하는 경우가 많다. 그 이유는 컴파일러나 혹은 초기 설정에 의해서 s값이 지정되는 경우가 많기 때문이다. 각 세그먼트가 메모리의 어디에 위치하는지는 운영체제에 의해 결정되며, 그 위치가 결정되면 그 정보, 즉 세그먼트 디스크립터는 디스크립터 세그먼트descriptor segment에 저장된다. 디스크립터 세그먼트는 세그먼트 디스크립터들을 모아 놓은 세그먼트이다. 디스크립터 세그먼트의 시작 위치는 디스크립터 베이스 레지스터desciptor base register라는 지정된 하드웨어 레지스터에 저장되어 있다. 디스크립터 베이스 레지스터는 프로세서 내부에 있는 레지스터이며, 디스크립터 세그먼트와 세그먼트들은 메모리에 만들어진다. 각 구조의 이름은 프로세서에 따라 다르게 표현되기도 한다.
페이징에서는 위의 세그먼트를 일정한 크기로 더 나눈다. 세그먼트는 크기가 일정하지 않으므로 메모리를 효율적으로 사용하기 어렵지만 페이징을 도입하면 더 작은 일정한 크기로 메모리를 다룰 수 있기 때문에 더 효율적이다.
세그멘테이션과 페이징이 멀틱스에서 처음 제안된 것은 아니다. 그리고 일부 시스템에서 구현된 바가 있었다. 멀틱스에서 적극적으로 도입된 이 기법들은 유닉스 시스템을 통해 널리 퍼졌다.
CTSS에서는 사용자 간의 메모리 영역 침해를 막기 위해 경계 레지스터bound register 라는 기법을 사용했었다. 경계를 넘어가는 접근은 원천적으로 금지한 셈이다. 그러다 보니 공유를 지원할 방법이 없었다. 그래서 멀틱스에서는 보다 고도화된 접근 제어가 도입되었다. 크게 두 가지 요소로 구성된다. 세그멘트와 링 레이어이다.
세그먼트는 메모리 영역을 의미한다. 그것은 프로그램 코드 덩어리일 수도 있고 데이터 덩어리일 수도 있다. 각 세그먼트에 대해 어느 정도의 접근을 허용할지를 지정할 수 있다. 누구나 다 접근할 수 있게 정할 수도 있고, 특정 권한을 가진 프로그램만 접근하게 할 수도 있으며, 최고 권한자만 접근하게 할 수도 있다. 그것을 결정하는 정보가 세그먼트 디스크립터에 설정된다.
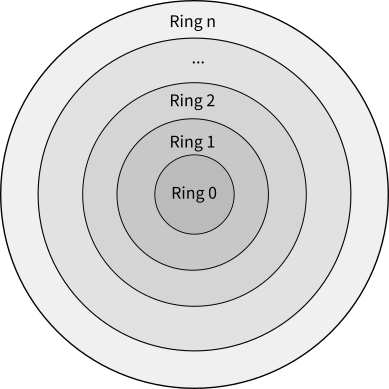
링 레이어는 세그먼트를 접근하는 권한을 아주 세부적으로 통제하게 해준다.8 링 레이어라는 이름에 너무 신경 쓸 필요는 없다. 각 세그먼트에는 링 번호라는 것이 부여된다. 링 번호가 낮은 세그먼트는 링 번호가 높은 세그먼트에 접근할 수 있지만 그 반대로는 불가능하다. 앞에서 설명했듯이 세그먼트는 프로그램 코드 덩어리일 수도 있다. 예를 들어 링 번호가 3번인 세그먼트가 있고 이것이 프로그램 코드라고 해보자. 그렇다면 이 코드는 링 번호가 5번인 세그먼트를 접근할 수 있다. 그 세그먼트는 데이터 덩어리일 수도 있고 아니면 다른 코드 덩어리, 예를 들어 라이브러리 함수일 수도 있다. 하지만 3번 세그먼트는 1번 세그먼트는 접근할 수 없다.
위의 그림은 말 그대로 개념을 보여주는 그림이다. 운영체제 내에 저런 형태의 데이터 구조가 있지는 않다.
파일 시스템
CTSS가 구현된 IBM 709 컴퓨터까지만 해도 자기 테이프를 저장장치로 사용했다. 테이프는 임의접근random access이 되지 않았으므로 효율적인 접근 구조를 만들기가 어려웠다. 따라서 사용자마다 파일 시스템이 제공되기는 했지만 계층화되어 있지는 않았다. 즉, 모든 파일들이 그냥 하나의 디렉터리(폴더)에 저장되는 식이었다.
자기 디스크 저장장치가 보급되면서 보다 정교하게 파일을 관리하기 용이해졌다. 멀틱스는 계층형 파일 시스템을 도입했다. 디렉터리 내에 디렉터리를 만들 수 있게 된 것이다. 이런 형태는 유닉스로 이어졌고 대중화되었다.
저장장치에 있는 파일의 내용을 프로그램이 접근하려면 그 파일에 있는 데이터의 위치를 지정할 수 있어야 한다. 멀틱스에서는 메모리 번지를 사용했다. 예를 들어 응용 프로그램에서 a.txt라는 파일의 내용을 읽으려면 가상 주소 공간 내의 0010000016 번지를 a.txt 파일의 첫 데이터 위치에 지정하는, 시스템 제공 함수를 사용한다. 그런 다음에 a.txt 파일의 첫 데이터를 가져오려면 가상메모리 주소 0010000016 번지를 읽으면 되고 두 번째 (바이트) 데이터를 가져오려면 가상 메모리 주소 00100000116 번지를 읽으면 된다.
이에 비해 유닉스는 파일을 다루는 별개의 시스템 제공 함수를 만들었다. 예를 들어 응용 프로그램에서 a.txt라는 파일의 내용을 읽으려면 fopen이라는 함수를 사용해서 파일 디스크립터file descriptor라는 전용 자료 구조를 생성한다. 파일 디스크립터가 생성되면 fread라는 함수를 사용해서 해당 파일 내의 데이터를 읽어온다. 파일 디스크립터에는 해당 파일을 관리하기 위한 각종 정보들이 저장된다.
고급 언어 사용
CTSS는 기계어/어셈블리어를 사용해서 개발되었다. 1960년에는 아직 알골 컴파일러가 제대로 만들어지기 전이었으므로 시스템 소프트웨어를 개발하기에 적합한 고급 언어가 존재하지 않았다.
기계어/어셈블리어는 작성하기도 어렵고 디버깅하기도 어렵다. 멀틱스와 같이 복잡한 구조의 소프트웨어를 기계어/어셈블리어로 구현하기는 참으로 쉽지 않은 일이다. 1964년에 IBM은 PL/I이라는 고급 언어를 개발하겠다고 발표했다. 포트란을 성공시킨 IBM이었으므로 PL/I에 대한 기대가 상당했으리라 짐작할 수 있다. 그래서 멀틱스 개발팀은 PL/I을 사용해 소프트웨어를 개발하기로 결정했다. 후에 유닉스가 대대적인 성공을 거두게 된 데는 C 언어가 큰 몫을 했다는 점에서 이는 전략적으로 올바른 선택이었다고 보인다. 하지만 이는 멀틱스가 실패한 가장 큰 이유가 된다. 왜냐하면 PL/I 컴파일러가 너무 늦게 나왔기 때문이다.
벨 연구소의 더그 맥클로이와 밥 모리스는 주위에서 인정하는 언어 전문가였고 또 이 프로젝트에서 프로그래밍 언어 쪽을 책임지고 싶어 했습니다. 그들은 PL/I이 좋은 선택이라고 믿었습니다. 그래서 우리는 그들이 원하는 대로 하도록 맡겼죠…
우리들이 내다보지 못했던 것은, 그놈의 언어가 너무 복잡해서 심지어는 컴파일러를 구현할 좋은 방법조차 생각해 내지 못할 정도였다는 겁니다. 그래서 처음에 구현한 컴파일러는 정말 엉망이었고 거의 동작하지 않았습니다…
우리는 더그 맥클로이와 밥 모리스가 직접 PL/I 컴파일러를 만들어 주길 기대했지만 그들은 외주를 주는 것이 가장 좋은 방법이라고 주장했습니다. 그래서 포트란 컴파일러를 만들어 본 회사를 선정했습니다…
그들은 결국 실패했습니다. 12개월인가 18개월을 날려 먹었습니다… 그래서 우리는 급하게 사람들을 모아 아주 원시적인 수준의 PL/I 컴파일러를 만들었습니다. 그리고 제너럴일렉트릭도 시도를 했죠. 밥 프라이버그하우스가 그 개발을 이끌었는데 결국은 상당히 좋은 PL/I 컴파일러를 만들어 냈습니다…
하지만 정말로 괜찮은 PL/I 컴파일러를 손에 넣기까지 3~4년이 흘러버렸습니다.2
셸 프로그램
셸shell은 프로그램이면서 동시에 사용 환경이다. 셸은 CTSS의 터미널 명령어 처리기에서 출발했다.11 CTSS에서는 사용자가 전자식 타이프라이터에 명령어를 입력하면 수퍼바이저가 이를 처리해 주었다. 이때까지만 해도 명령어를 처리하는 코드가 운영체제 내에 붙박이로 들어있었던 셈이다. MIT 컴퓨테이션 센터의 직원이었던 루이 푸잔Louis Pouzin는 CTSS를 좀 더 편리하게 쓰기 위해 두 가지 작업을 했다. 하나는 여러 개의 명령어들을 순서대로 수행해 주는 명령어 RUNCOM이다. 이는 오늘날의 셸 스크립트와 유사한 일을 한다. 또 하나는 명령어를 별개의 사용자 라이브러리로 구현한 것이다. 즉 명령어를 수퍼바이저 내에서 처리하는 것이 아니라, 일종의 서브루틴 호출하듯이 만든 것이다. 이렇게 되면 운영체제를 건드릴 필요 없이 명령어를 수정하거나 확장할 수 있게 된다.
루이 푸잔은 멀틱스 프로젝트 초기에 참여했는데 사용자가 입력하는 명령어를 처리해 주는 별개의 프로그램을 구현하자고 제안했고 셸shell이라고 이름 지었다.
셸 프로그램은 유닉스에 계승되었고 본 셸Borne shell이 나오면서 오늘날의 형태를 갖추게 되었다.
멀틱스의 완성
멀틱스 시스템이 제대로 동작하기 시작한 때는 1968년 말이었다. GE 645 컴퓨터에서 동작한 멀틱스는 기대에 미치지 못했다. 개발에 너무 오랜 시간이 걸렸을 뿐만 아니라 성능이 기대에 미치지 못했다. 결과에 실망한 벨연구소는 1969년에 프로젝트에서 탈퇴했다.**
멀틱스는 1969년 10월에 정식 서비스에 들어갔고 1970년대에는 하니웰Honeywell과 불Bull에서 정식으로 판매했다. 2000년에 마지막 멀틱스 시스템이 작동을 멈췄다. 현재는 오픈 소스로 공개된 상태이다.
멀틱스는 객관적으로 보면 성공한 시스템은 아니다. 유닉스라는 강력한 대체재에 가려져서 빛을 보지 못했다. 그 이유에 대해 코바토는 이렇게 말했다.
참여기관 세 곳의 (각기 다른) 목적들이 결국은 문제의 한 부분이었습니다… 그러나 이런 틀 속에 있는 가장 치명적인 약점 중 하나를 들라면, 아무도 책임지는 위치에 있지 않았다는 겁니다. 협력하자는 동의는 있었습니다. 제너럴일렉트릭과 MIT, 제너럴일렉트릭과 벨연구소 사이에는 계약서가 있었지만 MIT와 벨연구소 사이에는 계약서가 없었습니다. 그러다 보니 모든 일은 선의에 의해 움직였습니다. 2

답글 남기기